들어가면서

위 이미지는 현재 하루스터디의 DDL을 도식화한 ERD입니다. 간략하게 각 테이블을 엔티티 단위로 묶어서 설명해보면 다음과 같습니다.
- study : 하루스터디 서비스에서 개설되는 스터디에 대한 정보를 관리
- member_progress : 개설된 스터디에서 참여자들의 진행 정보를 관리
- member_record : 참여자들이 스터디의 각 사이클마다 진행한 사전 계획과 회고를 관리
- member : 참여자들의 개인 정보를 관리
- participant_code : 스터디 방 개설 후 입장 시 필요한 참여코드를 관리
여기에서 주목할 것은 study, member_progress, member_record 테이블입니다. 현재 ERD에서는 한 눈에 알아보기 힘들긴 하지만 이 테이블들은 전부 Join전략을 통해 엔티티간의 상속관계를 구현해내고 있습니다. study를 슈퍼타입으로 가지는 pomodoro는 스터디 진행에 필요한 총 사이클 횟수와 사이클 당 학습시간 정보를 관리합니다. 이와 비슷하게 member_progress, member_record를 각각 슈퍼타입으로 가지는 pomodoro_progress, pomodoro_record는 하루스터디가 현재 제공하는 뽀모도로 스터디 방식에 필요한 데이터를 관리합니다.
상속관계를 어떻게 DB 모델로 구현했는가?
팀 내 논의를 거쳐 하루스터디는 Join 전략을 사용해 상속관계를 구현하기로 결정했습니다. 그 이유는 이후 서비스를 확장하면서 제공하는 스터디의 종류가 늘어날 것이라고 생각했기 때문입니다. 그럴 때 테이블의 구조가 상속관계를 구현하고 있다면 새로운 스터디 종류를 추가하는 것이 더 쉬울 것이라는게 하루스터디 팀의 결론이었습니다.
해당 판단 과정에서 더 깊은 고민은 해보지 못했는데 나름대로의 근거를 더 구체적으로 세워보고자 했습니다.
(아래 내용부터는 학습 후 개인적으로 정리한 내용입니다.)
먼저 단일 테이블 전략을 사용했을 때 얻을 수 있는 장점들보다 단점들이 하루스터디 서비스에 더 크게 와닿는다고 생각했습니다.
현재 하루스터디는 스터디 내에서 계획 - 학습 - 회고 단계로 이루어진 짧은 사이클을 반복적으로 수행하도록 도와주는 서비스입니다. 흔하게들 알고 계시는 뽀모도로 스터디 방식과 유사합니다. 하지만 팀원들과 DB 구조를 설계하는 과정에서 추후에 뽀모도로 방식 외의 다른 스터디 방식도 지원하는 방향으로 서비스를 확장하게 될 가능성이 매우 높다고 판단했습니다. 예를 들면 세미나, 토론 방식 등으로도 스터디를 진행할 수 있는 기능을 추가할 수 있을 것입니다.
이럴 때 테이블 설계에서 슈퍼타입 - 서브타입 관계를 단일 테이블 전략으로 구현하고 있다면 어떤 장점과 문제점들이 생길 수 있을까요? 장점으로는 단일 테이블에서 모든 데이터를 관리하기에 조회쿼리가 굉장히 단순하다는 점과 Join 연산을 사용할 때 보다 속도가 빠르다는 점이 있습니다. 반면 문제점으로는 여러 서브타입 엔티티마다 다르게 갖는 데이터들로 인해 column에 null 값을 필연적으로 허용할 수 밖에 없다는 점, 분기점을 넘어서면 오히려 Join 연산을 사용할 때보다 성능이 안나온다는 점이 있습니다.
Join 전략을 사용할 때보다, 단일 테이블 전략에서의 조회 속도가 더 빠르다는 것은 일반적으로 맞는 이야기입니다. 하지만 실질적으로 하루스터디 서비스에서 성능적인 차이를 보일 만큼의 Join 연산이 많이 이루어질까에 대한 의문이 들었습니다. 또한 join 연산으로 인한 성능 이슈를 인덱스 활용을 통해 어느 정도 해소할 수 있었기에 단일테이블 전략의 장점은 상대적으로 더 불명확하게 느껴졌습니다.
반면 단일 테이블의 column에 필연적으로 null 이 저장되는 것은 저희 서비스에게 있어서 명확하게 단점으로 느껴졌습니다. 만약 현재 하루스터디가 제공하는 뽀모도로 방식 외에 다른 스터디 방식을 추가적으로 지원하게 되었을 때 단일 테이블 방식에서 테이블 구조는 어떻게 될까요?

현재 하루스터디 서비스의 study 테이블을 단일 테이블 전략을 사용해 설계해본다면 위와 같은 구조로 설계될 것입니다. 여기에 세미나와 토론 스터디 방식에 대한 데이터를 추가했다고 가정하고 테이블을 재설계 해보겠습니다.
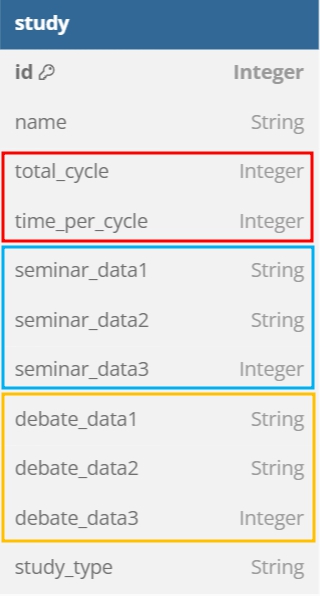
그러면 위와 같이 새롭게 추가된 세미나와 토론 방식의 데이터를 관리하기 위한 column들의 추가가 이뤄질 것입니다. 각각 빨간색, 하늘색, 노란색으로 구분된 column들이 보이시나요? 만약 서비스에서 뽀모도로 방식의 스터디가 새로 개설된다면, 세미나와 토론 방식 스터디 데이터에 해당하는 하늘색과 노란색 영역 데이터들이 전부 null 상태로 저장이 될 것입니다.
지금은 예시를 들어 스터디 방식을 2가지만 추가했고 각 스터디에서 필요로 하는 데이터 column을 3개로 제한했습니다. 하지만 실제로 서비스에서 몇 개의 스터디 방식이 추가되며 확장되어 갈지, 추가된 각 스터디에서 얼만큼의 데이터들을 관리해야 하는지 현재로서는 예상하기 쉽지 않습니다. 한 가지 확실한 건 서비스가 확장되어 갈수록 study 테이블에 null 상태인 column이 늘어만 갈 것이라는 것이죠.
테이블에 null 상태인 column이 존재한다는 것은 추가적인 단점들을 발생시킵니다. 일반적으로 알려진 3치 논리 방식으로 인한 모호함, 의도치 않은 쿼리 검색결과의 반환 등의 문제가 있을 수 있습니다. 하지만 이런 문제는 테이블의 dtype 컬럼으로 1차적인 필터링을 한 번 거친 후에 연산을 수행하도록 한다면 어느 정도 해결될 수 있을 것 같아 보입니다.
하지만 가장 큰 단점으로 와닿았던 것은 DB의 옵티마이저가 최적화를 수행하는데 제한을 걸어버린다는 점이었습니다. null의 존재는 수학적 증명의 불가능으로 인해 옵티마이저가 선택할 수 있는 최적화된 쿼리 조합 선택의 폭을 축소시키게 됩니다. 앞서 Join 전략의 단점을 개선하기 위한 방안이 상대적으로 쉽게 도출될 수 있었던 반면, 옵티마이저와 관련된 성능 문제는 현실적으로 하루스터디 팀에서 대응하기 힘들 것이라는 결론에 다다를 수 있었습니다.
결론
DB의 테이블 설계로 엔티티 간 상속 관계를 구현하는 방법들 중 Join을 이용한 방식과 단일 테이블 방식에 대한 장단점을 하루스터디 프로젝트 상황에 맞춰 정리해봤습니다. 이를 바탕으로 하루스터디에서 엔티티 간 상속관계를 DB 모델로 구현하기 위해 Join 전략을 선택한 이유에 대해 개인적인 근거를 정리해볼 수 있었습니다.
'우아한테크코스 > 학습 정리' 카테고리의 다른 글
| [Logging] Logback을 이용한 기본적인 로깅하기 (1) | 2023.08.06 |
|---|---|
| [Spring Data JPA] Save() 메서드 persist VS merge (0) | 2023.07.30 |
| 브랜치 전략에서 squash and merge 방식 사용에 대한 고찰 (0) | 2023.07.16 |
| Domain 그리고 Entity, VO에 대한 개인적인 고찰 (0) | 2023.06.07 |
| 스프링 @Transactional(readOnly=true)에 관한 간단한 고찰 (1) | 2023.06.04 |