들어가면서
현재 진행중인 프로젝트에서 구성했던 서버를 Scale Out 하게 되었습니다. 여기에는 여러가지 배경이 있었는데요, 가장 큰 이유는 앞으로 있을 크고 작은 업데이트를 적용할 때 무중단 배포를 수행하기 위해 블루/그린 배포 전략을 적용하기 위한 서버 이중화가 필요했었다는 것입니다. 그에 따라 배포 시에는 블루/그린 서버로 사용되지만 평소에는 nginx 로드 밸런싱 기능을 활용하여 트래픽을 분산처리할 수 있도록 하여 리소스를 최대한 효율적으로 사용하고자 했습니다.
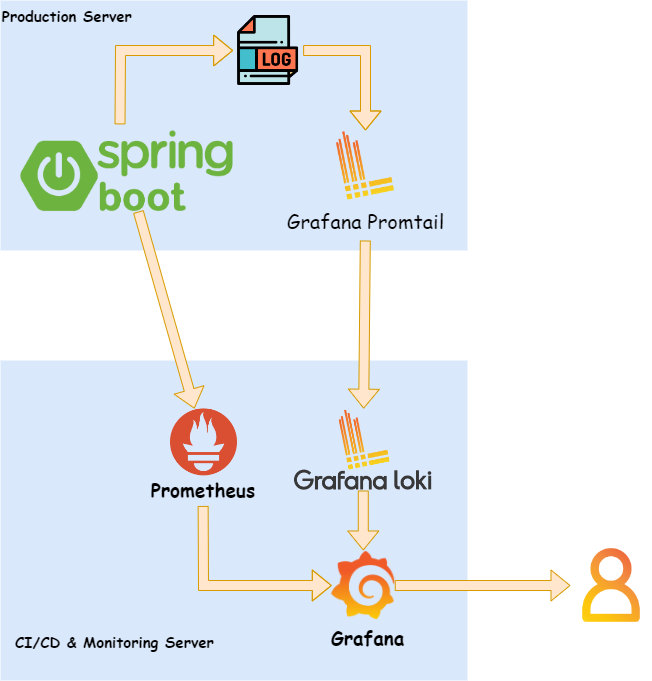
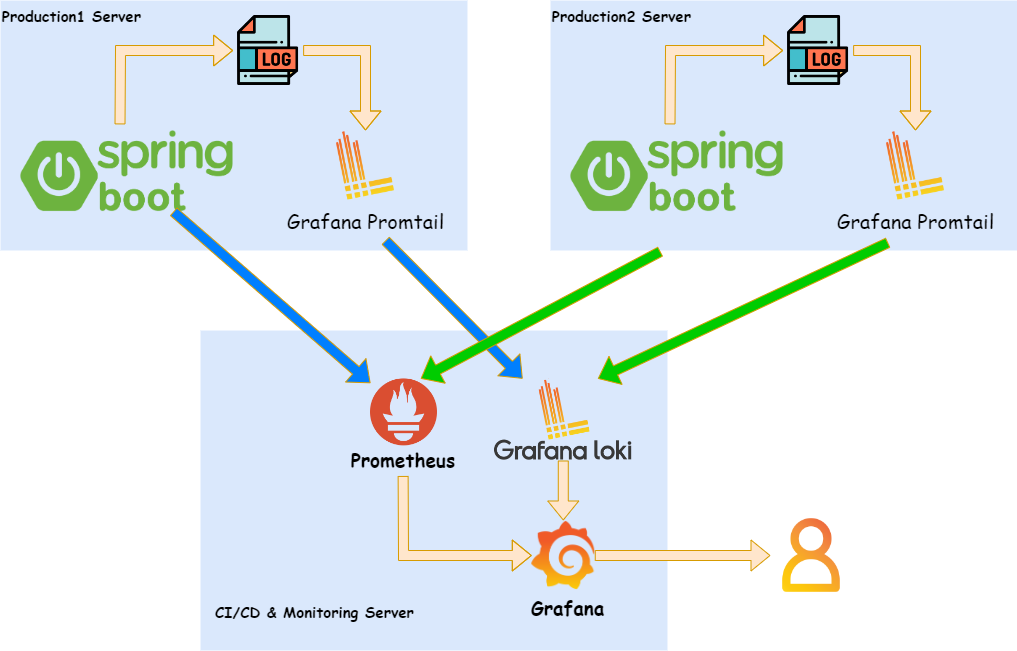
그런데 문제가 하나 있었습니다. 기존에는 단일 서버 환경에서 수행하던 로깅 데이터 모니터링이 정상적으로 동작하지 않는 문제였는데요. 그 원인은 서버가 이중화 되면서 한 곳에 저장되던 로깅 데이터가 각 서버에 나뉘어져 저장되기 시작했다는 것이었습니다. 규모가 큰 서비스였다면 로그 통합 처리 시스템을 따로 구축할 수 있었겠지만 현재 그러한 시스템을 구축할 수 있는 서버 자원과 인적 리소스를 투자하기는 현실적으로 힘든 상황이었습니다. 따라서 기존 모니터링 대시보드 툴인 그라파나에서 다중화된 서버에 저장된 로깅 데이터를 모니터링할 수 있는 방법을 모색하게 되었습니다.

기존 그라파나 로키의 설정창입니다. 저희는 각 서버에서 다른 job 이름으로 수집되는 로깅 데이터를 함께 조회하고 싶기에 label filter에 job을 추가해주면 될 것 같습니다. 하지만 그라파나 로키의 쿼리 빌더는 2개 이상의 job filter를 추가하는 기능을 제공하지 않았기에 해당 문제를 해결하기 위해 공식문서를 아래 내용과 같이 참고하였습니다. (본 포스팅에서는 프롬테일 설정은 자세하게 다루지 않으므로 참고 부탁드립니다.)
해결 과정
LogQL : Log Query Language
LogQL은 그라파나 로키의 PromQL-Inspired 쿼리 언어입니다. 작성한 쿼리들은 각 로그 소스들을 통합하기 위해서, 마치 grep 명령어를 각 로그 소스들을 대상으로 분산처리하는 것과 같이 동작하게 됩니다. LogQL은 필터링을 위해 label과 operator를 사용합니다.
LogQL 쿼리의 종류에는 다음과 같은 2가지 종류가 있습니다.
- Log Queries : 로그 라인들의 내용을 반환합니다.
- Metric Queries : 쿼리 결과에 기반을 두고 추가적으로 값을 계산해서 Log Query를 확장하는 개념의 쿼리입니다.
저희는 각 서버에 저장된 로그 데이터를 그대로 출력하는 것이 목표이기 때문에 Log Queries를 좀 더 알아보면 될 것 같습니다.
Log Queries
모든 LogQL 쿼리들은 작성될 때 log stream selector를 포함합니다. stream selector는 여러 로그 스트림들 중 어떤 스트림이 쿼리 결과에 포함될지를 결정합니다. 로그 스트림은 로깅 파일과 같이 로그 내용이 담겨있는 고유한 출처를 의미하는데 stream selector를 통해서 발견된 여러 스트림 중 필요한 스트림을 선택할 수 있습니다. 너무 많은 스트림이 존재하는 경우 쿼리의 성능을 위해 stream selector에 적절한 label을 지정할 수도 있습니다.
log stream selector는 ,(comma)로 분리된 여러 쌍의 키 - 값 형태로 명시됩니다. 그리고 이 여러 쌍의 키 - 값 데이터들을 { } 로 감싸서 stream selector를 구분합니다.
{app="mysql",name="mysql-backup"}위 예제의 log stream selector는 모든 로그 스트림들 중에서 명시된 키 - 값의 label들을 가지는 스트림들만 쿼리 결과에 포함시키게 됩니다. 여기에서 = 연산자는 label matching 연산자입니다. log stream selector에서는 다음과 같은 label matching 연산자들을 지원합니다.
- = : 정확하게 일치
- != : 일치하지 않음
- =~ : 정규식에 부합함
- !~ : 정규식에 부합하지 않음
공식 문서에 소개된 정규식 관련 연산자 예제는 다음과 같습니다.
{name =~ "mysql.+"} // mysql 이후 어떤 문자가 하나 이상 오는 문자열을 모두 포함
{name !~ "mysql.+"} // mysql 이후 어떤 문자가 하나 이상 오는 문자열을 모두 미포함
{name !~ `mysql-\d+`} // mysql 이후 하이픈 + 한자리 이상의 숫자가 오는 문자열을 모두 미포함
기존 자동 생성된 Log Query 수정하기
서버 Scale Out 이전에 그라파나에서 사용하던 자동 생성된 쿼리는 다음과 같았습니다.
{job="production_http_log"} |= ``해당 log stream selector는 job label의 값이 "production_http_log"인 로그 스트림만 쿼리 결과에 보여주도록 하고 있습니다. 위에서 살펴봤던 대로 이 log stream selector에 명시된 label에서 정규식을 사용하도록 하면 저희가 원하는 대로 여러 서버에서 다르게 수집되는 로그 스트림들을 같이 조회할 수 있을 것 같습니다. (뒤에 붙은 |= `` 표현식은 로그 라인에 해당 문자가 포함되어 있으면 쿼리 결과에 포함시키겠다는 의미인데 그라파나 쿼리 빌더가 자동으로 붙여준 것이라 이후 설명에서는 생략하겠습니다.)
현재 저희 프로젝트 서버를 Scale Out 하고 난 뒤 검색되는 로그 스트림들의 job label의 현황은 다음과 같습니다.

production1, production2 라는 이름으로 구분되어 labeling이 되어 있는 것을 확인할 수 있습니다. 여기에서 보여지는 job 이름들은 각 서버 로컬에서 프롬테일을 실행할 때 사용하는 설정 파일에 명시되어 있습니다.
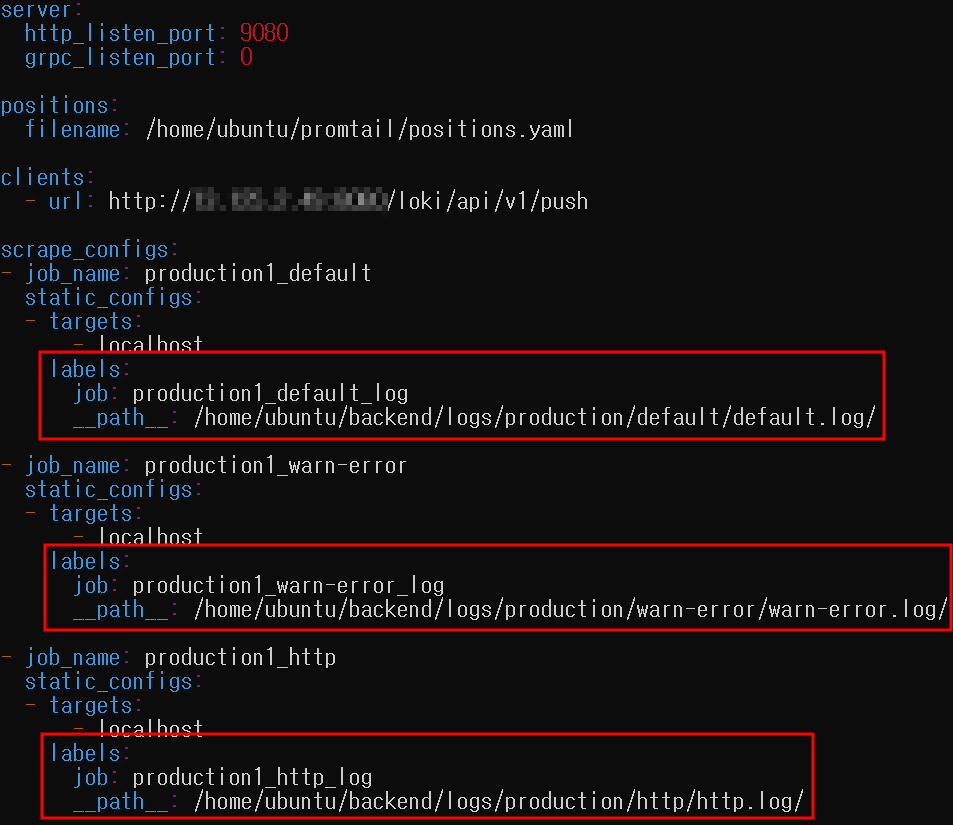
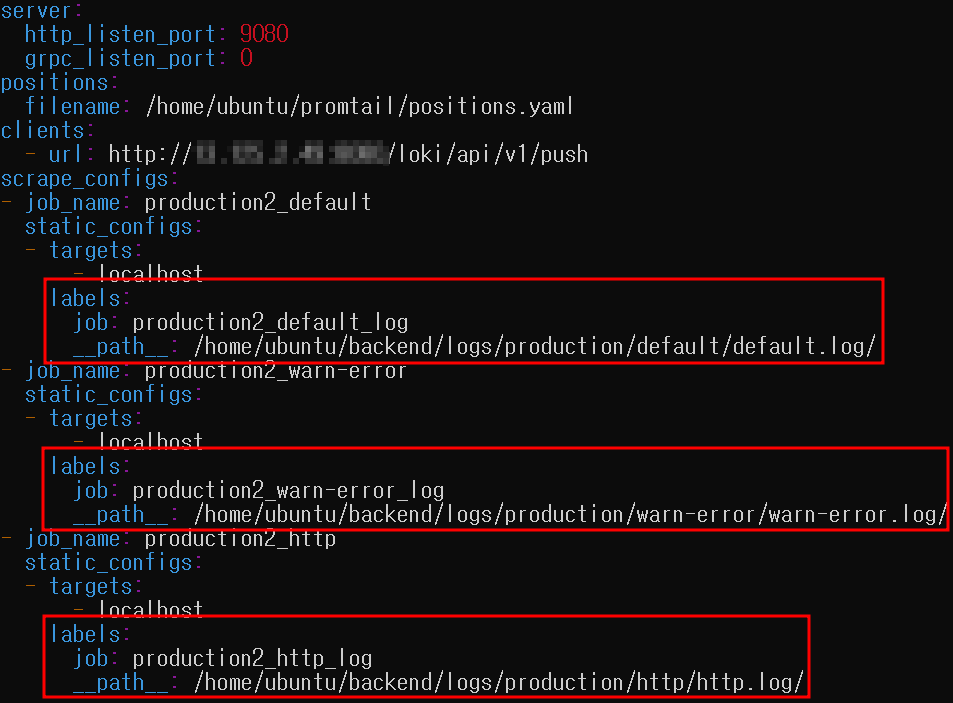
따라서 저희는 production1, production2에 각각 기록되어 들어오는 로그 스트림을 함께 조회하고 싶으므로 다음과 같은 정규식이 포함된 log stream selector를 작성했습니다.
{job=~"production[12]?_http_log"}
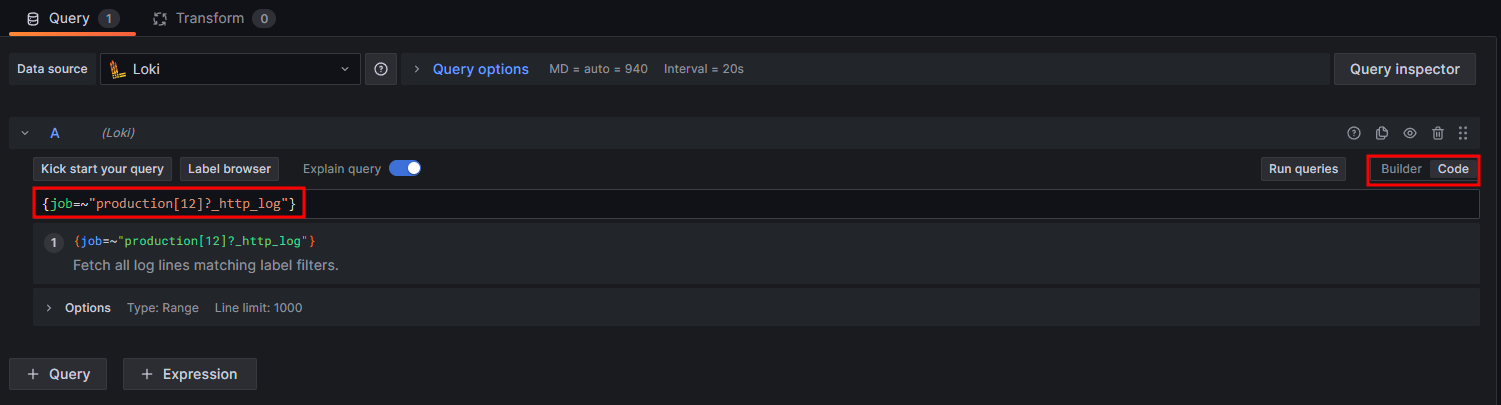
이렇게 각 로그 패널 별로 production1, production2의 로그 스트림을 통합해서 보여주도록 함으로서 다시 하나의 패널에서 여러 서버로 분산 처리되어 기록되는 로그를 확인할 수 있게 되었습니다.
마치며
지금까지 그라파나 로키에서 사용하는 쿼리는 어떤 것인지 알아보고 이를 기반으로 모니터링할 로그 스트림을 조회할 수 있는 쿼리를 정규식을 사용해 작성했습니다. 이를 기반으로 다중화된 서버 환경에서 분산 저장된 로깅 데이터를 그라파나를 통해 모니터링할 수 있었습니다. 해결하고나면 굉장히 간단한 방법이지만 그라파나 로키에 대한 이해도가 낮은 상태에서 처음 문제를 접했을 때는 해결책을 떠올리기 쉽지 않았기에 해결과정을 기록으로 남겨둡니다. 혹여 잘못된 내용이 있다면 피드백 댓글로 달아주시면 감사하겠습니다!
Reference
'우아한테크코스 > 학습 정리' 카테고리의 다른 글
| [최적화] Tomcat 스레드 풀 튜닝에 대한 고찰 (1) | 2023.09.24 |
|---|---|
| [DB] 인덱스 기본 개념과 클러스터링, 논클러스터링 인덱스 (2) | 2023.09.17 |
| [Logging] Slack 알림 메세지 Logger 구현하기 (1) | 2023.08.28 |
| [Logging] Logback을 이용한 기본적인 로깅하기 (1) | 2023.08.06 |
| [Spring Data JPA] Save() 메서드 persist VS merge (0) | 2023.07.30 |