![[우아한테크코스] LV3 - 3차 스프린트 회고](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Ft1rBX%2FbtsrBZ10XTL%2FAAAAAAAAAAAAAAAAAAAAAD94VyD_NHQecvK3ZO_jfLr3prTw3aAG0IEvbRrRSr2t%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3Dss7tpvH%252FkYoSfPDLINxUp5VCZm0%253D)

들어가면서
3차 스프린트는 서비스 배포와 내부 설계 변경에 집중했던 기간이었다. 처음엔 프론트엔드와 백엔드 모두 기능적으로는 구현이 완료된 상태였기에 배포 과정에서 큰 문제는 없을 것이라 판단했었다. 그러나 예상과는 다르게 기본적인 비즈니스 플로우의 시작점에서부터 에러들이 발생하기 시작했다. 이러한 에러들을 해결하며 기능 연동을 위해 노력하는 한편 백엔드 팀에서는 내부 구조에 대한 논의와 변경이 많이 이뤄졌었는데 이를 정리하고자 한다.
3차 스프린트
CloudFlare 캐시 삭제 문제
하루스터디 팀에서는 프론트엔드와 백엔드 별 기능 구현이 1차적으로 완료되고 나서 정식 배포를 위해 기능 연동을 진행했다. 실제로 연동이 잘 되었는지 확인하기 위해 개발 서버에 배포를 완료한 후 배포된 서비스에 접근해서 직접 서비스 플로우를 검증하는 방식으로 테스트를 진행했다. 해당 과정에서 발생하는 에러들을 수정하고 배포하고 다시 확인하는 작업을 반복할 수 밖에 없었다. 그런데 분명 수정해서 배포를 완료했음에도 불구하고 변경사항이 제대로 반영되질 않는 문제가 발생했었다.
팀 내 트러블슈팅 결과 변경사항이 반영되지 않은 이전 파일이 캐싱되어 있어서 변경사항이 반영된 파일을 불러오지 못하는 것이 문제라고 판단할 수 있었다.
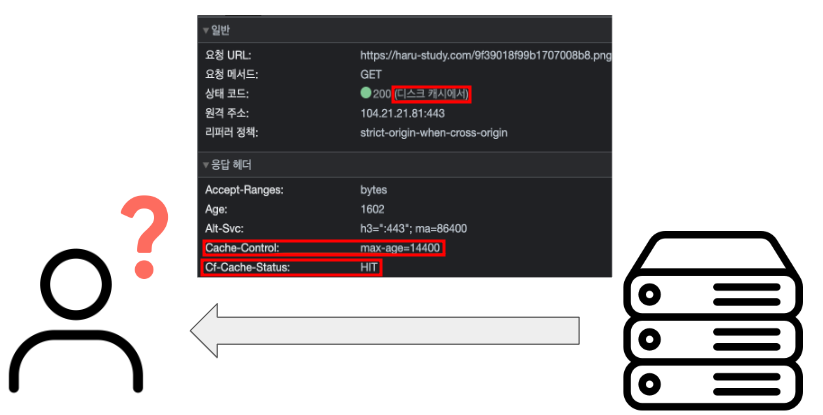
변경사항이 발생한 페이지 요청에 대한 응답 메세지를 확인했을 때 위와 같은 상태로 내려왔다. 응답 메세지의 상태코드 옆에 괄호로 `디스크 캐시에서`라는 문구가 추가로 내려온다. 또한 응답 헤더에는 `Cache-Control`과 `Cf-Cache-Status`에 각각 값이 들어있는 것을 확인할 수 있다. 이러한 캐싱작업들은 하루스터디 팀에서 CloudFlare를 통해 HTTPS 프로토콜을 적용했기 때문에 발생했던 문제였다.
CloudFlare에서는 브라우저 캐싱과 CDN 캐싱, 크게 2가지 방식으로 캐싱을 진행한다. 브라우저 캐싱은 서비스 사용자의 브라우저에 페이지 파일 정보를 캐싱해두고 동일한 리소스 요청시 이를 서버에 요청하지 않고 캐싱된 파일을 바로 반환하도록 하는 방식이다. 'Cache-Control' 헤더 값을 보면 max-age=14400으로 되어 있어서 14400초, 즉 4시간 동안 동일 요청에 대한 응답 내용을 캐싱하겠다는 의미이다.
CDN 캐싱에서 CDN은 Content Delivery Network의 약자로 지리적으로 더 가까운 서버에 정적 데이터를 캐싱함으로써 응답 속도를 높이는 방식이다. `Cf-Cache-Status` 헤더에 값이 HIT라고 담겨있는는데 이는 해당 요청에 대한 응답이 CloudFlare에서 자체적으로 운영하는 CDN 서버에서 캐싱 HIT된 것임을 표시한다.
이렇듯 2가지 방식으로 content들이 캐싱되어 있어서 변경사항을 반영하고 배포하더라도 배포된 서비스에서 직접 확인이 불가능했던 것이다. 이를 해결하기 위해 CloudFlare 상에서 캐싱 옵션을 해제하고 캐싱되어 있는 데이터를 삭제(Purge) 해주었다. 더 자세한 해결방법은 하루스터디 팀 블로그에 테오가 잘 정리해줘서 참고하고자 하는 사람들을 위해 링크를 남겨둔다.
Flyway 도입
하루스터디 팀에서는 배포 과정에서 테이블 구조를 변경해야 하는 수정사항이 생각보다 빈번하게 발생했었다. 처음에는 개발서버 DB 콘솔에서 직접 DDL을 조작하며 진행했다. 하지만 실제 서비스를 배포한 뒤 운영 DB 서버에서는 DDL을 계속 이런 방식으로 관리할 수는 없겠다는 것을 인지했는데 그 문제들은 다음과 같았다.
- 직접적인 DDL 조작의 위험성
- 현재는 사람이 직접 DB 콘솔에서 DDL을 입력하는 방식인데 휴먼에러가 발생할 확률이 매우 높다. 이는 실제 서비스 운영에 치명적인 결함으로까지 이어질 수 있다.
- DB 서버 접근이 매우 번거로움
- 현재 DB 서버는 우테코 private IP로 캠퍼스 내 네트워크에서만 접근이 가능하다는 제약사항이 존재했다. 그래서 위에 언급했던 위험성과는 별개로 실행중인 DB 서버에 변경사항을 반영하기 위한 DDL을 실행시킬 수 있는 다른 방법이 필요했다.
- DDL 변경사항에 대한 추적이 어려움
- 초기 DDL에서 변경사항이 생겼을 때 형상관리가 되지 않으면 언제 어떤 순서대로 변경사항이 생겼는지 알 수 없다.
따라서 하루스터디 팀에서는 DB 마이그레이션 도구인 Flyway를 도입했고 아래 이미지와 같이 DDL을 형상관리할 수 있도록 함으로써 위의 문제들을 해결할 수 있었다.
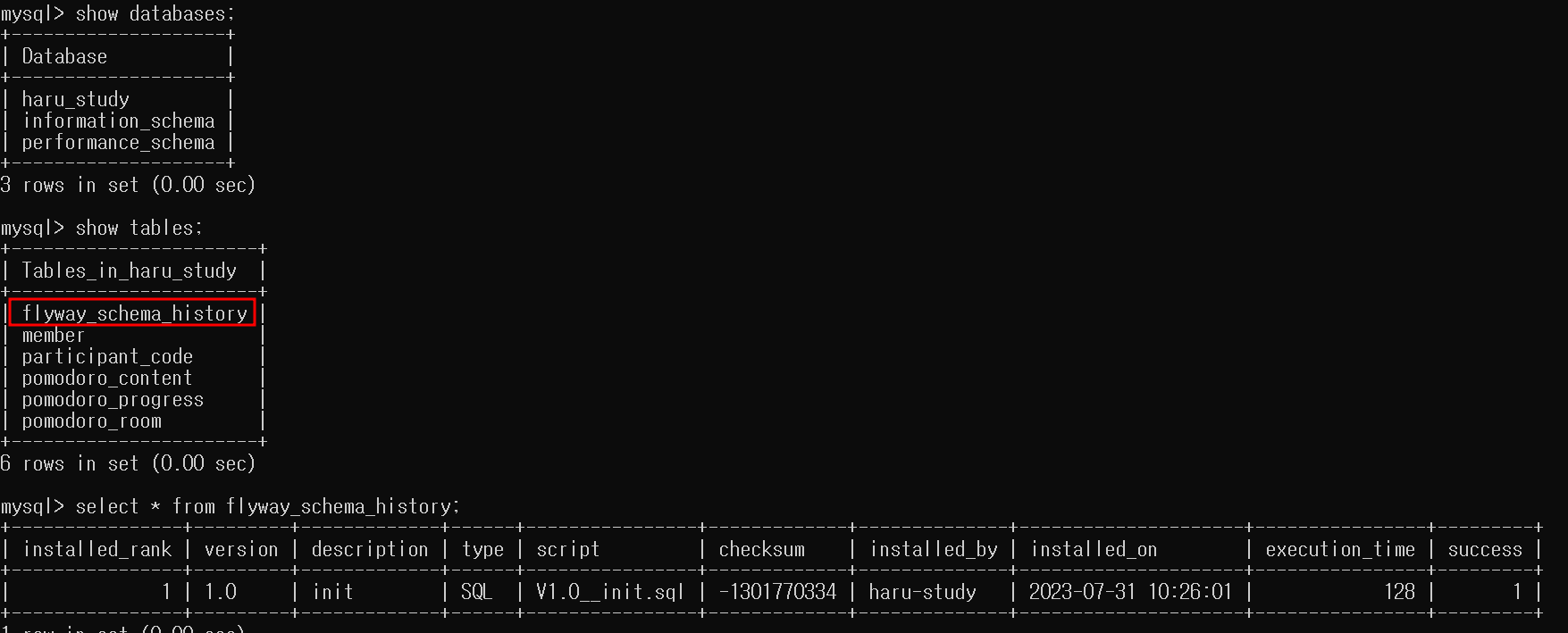
이후 Oauth2.0을 이용해서 로그인 기능을 신규 구현할 때 대대적인 엔티티 설계와 DB 테이블 구조에 변화가 발생하게 되었다. 이 때 Flyway를 활용해서 새롭게 적용되어야할 DDL을 다음과 같이 추가적인 sql 파일로 관리하며 적용할 수 있었다.
// V1.1__add-auth.sql
alter table pomodoro_progress add column nickname varchar(255);
alter table pomodoro_progress modify nickname varchar (255) not null;
alter table member drop column nickname;
alter table member
add column name varchar(255),
add column email varchar(255),
add column image_url varchar(255),
add column login_type enum ('GUEST', 'GOOGLE');
alter table member modify name varchar (255) not null;
alter table member modify login_type enum ('GUEST', 'GOOGLE') not null;
alter table pomodoro_progress modify pomodoro_status enum ('PLANNING','RETROSPECT','STUDYING', 'DONE') not null;
alter table pomodoro_progress drop column is_done;
CREATE TABLE `refresh_token`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`member_id` bigint DEFAULT NULL,
`UUID` binary(16) NOT NULL,
`expire_date_time` datetime(6) NOT NULL,
`created_date` datetime(6) NOT NULL,
`last_modified_date` datetime(6) NOT NULL,
PRIMARY KEY (`id`)
);
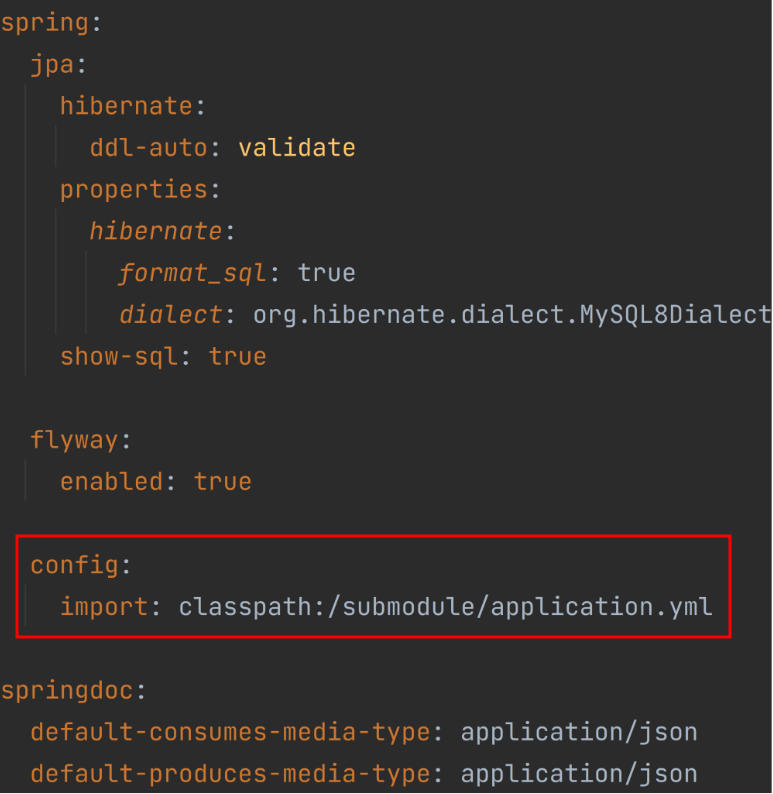
mysql 접속 정보 보안 관리를 위한 서브모듈 적용
jar파일이 실행되는 서버와 MySQL DB 서버를 분리해서 운용하다보니 프로젝트 yml 파일에 db 접근을 위한 정보를 관리했어야 했다. 그렇다 보니 기존 application.yml 파일에는 하루스터디 DB 서버에 접속할 수 있는 username과 password 정보등이 포함되어 있었다.
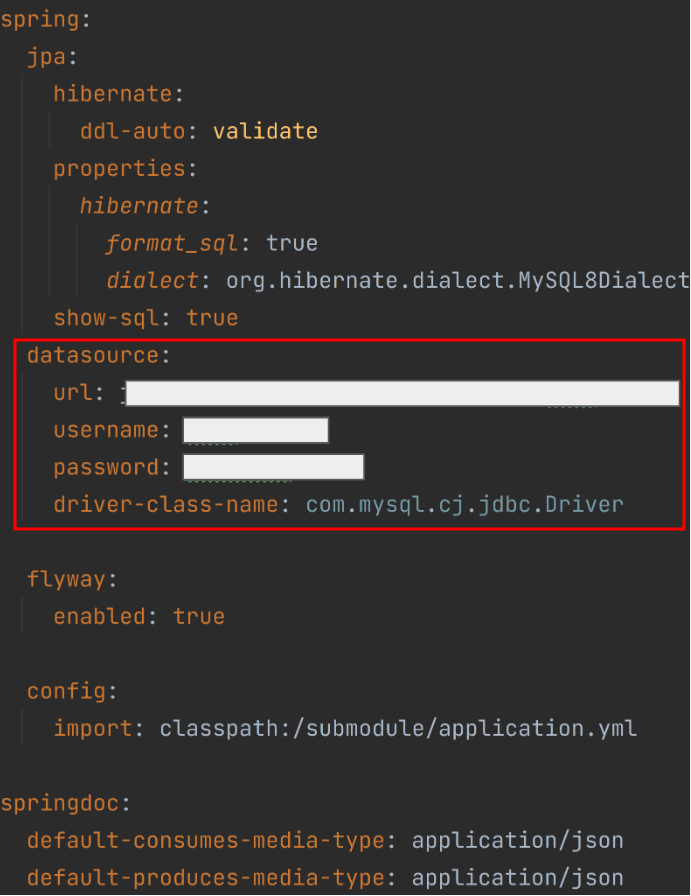
이러한 정보가 github 상에 노출되어 버리면 실 서비스 데이터가 저장된 DB에 누구나 접근할 수 있다는 심각한 보안 문제를 야기했다. 물론 1차적으로 AWS 보안그룹, VPC과 같은 안전 장치들이 존재하지만 보안문제는 애시당초 문제의 싹을 제거하는 것이 맞다고 판단했기에 서브모듈을 적용해서 민감한 정보들을 분리해 관리하도록 했다.
엔티티, DB에서 상속관계 제거
기존 하루스터디에서는 여러 종류의 스터디 템플릿을 제공하는 방향으로 서비스 고도화를 생각했기에 엔티티 설계에서 상속 구조를 채택했고 이를 DB 스키마 설계에도 반영했었다. 하지만 2차 스프린트 회고에 기록해뒀던 것처럼, 막상 개발을 진행하면서 상속구조를 채택한데서 오는 불편함이 너무 많았다.
- 엔티티 조회 이후 부모타입에서 자식 타입으로 항상 형변환해서 사용해야만 한다는 문제
- 반강제적인 제네릭을 통한 repository 구현으로 개발자가 항상 구현체 타입을 관리해줘야 한다는 문제
- 비즈니스 로직에 필요한 필드 값 위치 혼동 등 엔티티 관리 및 사용 시 복잡도 증가 문제
부모 타입 엔티티만을 필요로 하는 로직의 경우처럼 불가피하게 상속구조를 사용해야만 한다면 모를까 아직 그런 상황이 오지 않은 시점에서 위와 같은 불편함과 문제들을 떠안으며 상속구조를 유지해야할 이유가 없다고 팀에서 결정하게 되었다.

결과적으로 처음부터 간단하게 설계했었으면 될 일이었는데 돌아간 꼴이 되었다. 하지만 상속구조를 언제 사용해야 할지에 대한 기준을 생각할 수 있었고 무분별한 상속구조의 도입은 생각보다 큰 리소스를 요구한다는 것을 경험적으로 깨달을 수 있었다는데 의의를 찾고 싶다.
API 재설계
맨 처음 API를 설계할 때는 엔티티와 DB 테이블을 고려하지 않고 페이지 단위로 필요한 데이터들만을 고려했다. 백엔드 팀원들 모두 처음 설계할 때 당시 서비스 기획이 분명하지 못했고 계속 변경되는 상황이었기에 비즈니스 로직에 대한 이해도가 떨어져서 자연스레 서비스 페이지 단위로 API를 설계하게 되었다고 생각한다. 아래는 페이지 단위로 설계되었던 API 중 하나인 스터디 메타데이터 조회 API이다.
@RequiredArgsConstructor
@RestController
public class StudyController {
private final StudyService studyService;
@GetMapping("/api/studies/{studyId}/metadata")
public ResponseEntity<StudyAndMembersResponse> findStudyMetaData(@PathVariable Long studyId) {
return ResponseEntity.ok(studyService.findStudyMetadata(studyId));
}
}public record StudyAndMembersResponse(String studyName, Integer totalCycle, Integer timePerCycle,
List<MemberDto> members) {
}
이 API는 스터디 생성 시 입력된 정보와 더불어서 스터디에 참여하고 있는 멤버들의 정보를 함께 반환한다. 한 번의 요청으로 페이지에서 필요로하는 모든 데이터를 한 응답에 담아서 반환하고 있는데 이런 API로 인해 발생했던 문제들은 다음과 같았다.
- API에 매핑되는 URI가 정확하게 어떤 리소스를 타겟팅하는지 알 수 없다.
- 리소스 단위로 설계되지 않은 API이기에 어떤 controller에 위치해야 하는지 항상 논란의 중심이 된다. 위에서 예시로 든 스터디 메타데이터 API만 하더라도 이걸 StudyController에 위치시켜야 하는지 아니면 memberController에 위치시켜야 하는지 항상 고민해야 한다는 문제가 발생한다.
- 클라이언트 단에서의 특정 View의 편의를 위한 API이다.
- 이는 곧 API가 클라이언트의 특정 페이지를 의존하고 있다는 말과 동치이며 이는 곧 프론트 단에서 생기는 페이지 단위 기능 변경이 백엔드 API 에도 영향을 미치게 된다는 것을 의미한다.
- 또한 특정 페이지에서 사용하는 것만을 목적으로 설계된 API이기에 재사용성이 리소스 단위로 설계된 API보다 훨씬 떨어진다.
- 물론 성능상의 문제 등을 해결하기 위해 설계된 View 편의 API라면 이를 허용할 명분이 있겠지만 지금은 그러한 경우가 아니다.
- 이후 새로운 API를 설계할 때 들여야 하는 팀 논의 비용을 줄이기 힘들다.
- 이렇게 View 편의 API를 명확한 기준 없이 허용하기 시작하면 이후 새로운 API를 설계할 때 어떤 경우에 View 편의 API로 설계할 지, 리소스 단위 API로 설계할 지 항상 팀적으로 논의가 이뤄져야만 하며 이는 상당한 비용으로 이어진다.
이제와서 보니 참 문제가 많은 API였는데 그 때 당시 우리의 최선이었다고 생각하니 마음이 아팠다. 이를 프론트엔드 크루들과 논의 끝에 API를 리소스 단위로 재설계하기로 결정했다. 사실 이 부분은 우리가 좀 더 경험이 있었어서 API 설계를 처음부터 리소스 단위로 잘 설계했다면 2번 작업할 일이 없었을텐데 잘 수용해준 프론트 크루들에게 많이 고마웠던 부분이었다. 이후 프론트 크루들이 API를 뒤집어 엎는 과정에서 생각보다 큰 고생을 했고 많이 힘들었다고 얘기해줬는데 참 미안함이 많이 남았던 부분이었다. 다시 한 번 프론트 크루들에게 감사함과 미안함을 전한다.
따로 분리해서 업로드할 포스팅
생각보다 다룰 내용이 너무 많아지기도 했고 이론적인 내용을 한 번 더 정리해서 같이 포스팅해보고 싶은 내용들이 있어 추후 따로 포스팅해보려고 한다.
- room - progress - content 엔티티 간 cascade 이슈 (07.25)
- 테스트 과정에서 entityManager flush & clear 사용 이슈 (07.26)
- 피처 별 패키지 구조 변경
회고 마무리
회고를 하며 무엇을 했었는지 정리하다보니 3차 스프린트 기간에 했던게 굉장히 많았다는 것을 알게 되었다. 하지만 리팩토링이나 재설계와 같은 부분이 많았던 거지 새로운 서비스 기능이 추가된 것은 아니었기에 그 때 당시에는 2주 동안 뭘 한건가 싶기도 했던 생각이 들었던 게 기억이 난다. 거기에 3차 데모데이 발표자였는데 추가적인 발표 요구사항이 많이 늘어났었어서 심적으로 부담도 많이 되었던 것 같다. 그래도 큰 실수 없이 발표까지 마무리하고나니 많이 후련했다. 다음 4차 스프린트 회고때는 하루스터디 서비스의 새로운 기능들을 구현하며 마주했던 문제들과 해결방안들을 정리해보고자 한다.
'우아한테크코스 > 회고' 카테고리의 다른 글
| [우아한테크코스] LV3 - 4차 스프린트 회고 (0) | 2023.09.06 |
|---|---|
| [우아한테크코스] LV3 - 2차 스프린트 회고 (2) | 2023.08.13 |
| [우아한테크코스] LV2 - 웹 장바구니 협업 미션 회고 (2) | 2023.08.13 |
| [우아한테크코스] LV3 - 1차 스프린트 회고 (2) | 2023.07.09 |
| [우아한테크코스] 중간 회고 (2) | 2023.07.02 |