
들어가면서
최근 진행하고 있던 모각코 스케쥴러 사이드 프로젝트에서 검색어 자동완성 기능이 필요하여 개발하게 되었습니다. 모각코 일정을 생성하는 사용자는 해당 모각코에 모인 사람들이 어떤 기술 스택을 사용하는지, 어떤 키워드의 영역을 주로 다루는 사람들인지 간편하게 표시할 수 있도록 하기 위해 해시태그를 설정할 수 있습니다.

이 때 사용자는 해시태그를 직접 입력하게 되는데, 입력하는 문자열에 따라 기존에 생성되어 있던 해시태그를 추천받아 선택해서 사용할 수 있어야 합니다. 우선은 입력받은 문자열을 기반으로 DB 단에서 직접 필터링하여 조회해오는 가장 간단한 방식으로 구현한 뒤, 예상되는 문제점에 맞춰서 개선해보려고 합니다.
요구사항 정리 및 설계
해시태그 검색어 자동완성 및 추천 기능에 대한 요구사항을 간단하게 정리해보면 다음과 같습니다.
- 해시태그는 공백문자를 포함한 알파벳 소문자로 구성된다고 제한한다.
- 해시태그 길이는 최대 20 이하이다.
- API 응답 속도는 100ms 이내여야 한다.
- 자동완성은 입력된 문자열을 prefix로 갖는 해시태그들을 대상으로 한다.
- 자동완성 문자열은 모각코 일정에 많이 사용된 횟수를 기준으로 내림차순 정렬한다.
- 자동완성 문자열 후보군 반환 개수는 5개로 제한한다.
구현하기
앞서 정의된 요구사항을 충족하는 해시태그 검색어 자동완성 및 추천 API를 구현했습니다. 프로젝트에서 사용중인 Spring Data JPA를 활용하여 간단하게 구현할 수 있었습니다. 먼저 주어진 단어에 대한 일치 여부 검색은 DB 단에서 LIKE 명령어를 통해 필터링하는 방식으로 간단하게 해결했습니다.

문제는 가장 많이 사용된 해시태그 개수 별로 내림차순 정렬을 하는 부분이었는데, 초기 테이블 설계에서는 해시태그 테이블에서 따로 값을 관리하지는 않았기 때문에 중간 테이블과 Join 수행 후 count() 작업을 수행하는 방식으로 해시태그 별 사용된 횟수를 계산할 수 있도록 했습니다. 이렇게 만들어진 쿼리는 아래와 같았습니다.
public interface HashtagRepository extends JpaRepository<Hashtag, Long> {
@Query("select h " +
"from Hashtag h inner join MogakoHashtag mh on h.id = mh.hashtag.id " +
"where h.name like :word% " +
"group by h.id " +
"order by count(h.id) desc " +
"limit 5")
List<Hashtag> findTop5ByNameStartingWith(@Param("word") String word);
}

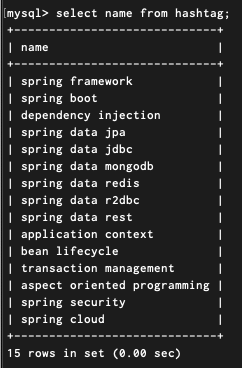
이렇게 가장 간단한 방식으로 API 구현을 빠르게 완료할 수 있었습니다. 15개의 해시태그를 삽입하고 조회를 해보면 위와 같이 정상적으로 조회되는 것을 확인할 수 있었습니다.
성능 측정 및 문제점 분석
15개의 해시태그 데이터에 대해서는 빠르게 조회되는 것을 확인했지만, 서비스에서 사용되는 해시태그 개수가 많아질수록 생기게 될 위험은 없는지 성능 측정을 해보기로 했습니다. 여기에서 개인적으로 예상되는 문제 상황은 두 가지였습니다.
- 해시태그 개수 자체가 많아지는 경우 (hashtag 테이블 레코드 증가)
- 해시태그 개수는 고정이지만, 모각코 일정에서 사용하는 해시태그 개수가 늘어나는 경우
(mogako_hashtag 테이블 레코드 증가)
두 가지 경우 중 해시태그 개수 자체가 많아지는 경우보다는 모각코 일정에 매핑되는 모각코 해시태그 개수가 많아지는 경우가 더 서비스에서 잦은 상황이라고 판단해서 해당 상황에 대해서 먼저 테스트를 진행했습니다. hashtag 테이블에는 총 15건의 해시태그 레코드를 아래와 같이 생성하고 테스트 과정에서는 고정으로 사용했습니다.
그리고 모각코 일정에 매핑되는 해시태그 개수를 점진적으로 늘려가며 API 처리 속도를 기준으로 성능 측정을 진행했습니다.
(이미지가 생각보다 많아서 접은 글로 작성했습니다.)
1500개인 경우

15000개의 경우
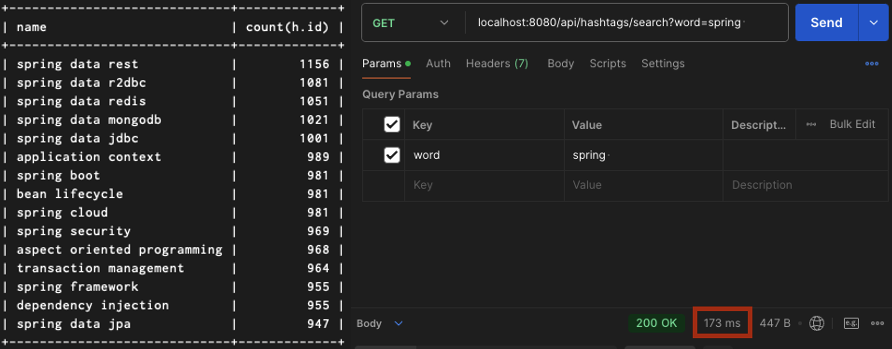
15만개의 경우
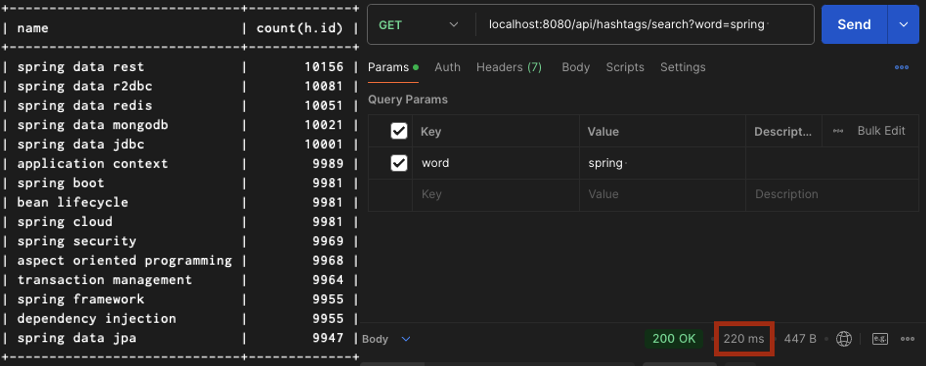
150만개의 경우

성능 측정 결과를 표로 간략하게 정리해보면 다음과 같았습니다.
| mogako_hashtag 테이블 레코드 수 | API 응답 시간 |
| 1,500건 | 16ms |
| 15,000건 | 173ms |
| 150,000건 | 220ms |
| 1,500,000건 | 761ms |
약속의 150만건의 레코드에서는 압도적인 성능 저하가 발생함을 확인할 수 있었습니다.
이렇게 성능 측정을 통해, 해시태그의 전체 개수는 15개밖에 안되지만 해당 해시태그를 사용하는 모각코 일정이 늘어남에 따라 점진적인 성능 저하가 발생함이 자명해졌습니다. 성능 저하의 주된 원인은 해시태그 자동완성 후보군에서 사용된 횟수를 기준으로 내림차순 정렬하기 위해 발생하는 조인 연산과 count 쿼리 때문이라고 추론했는데요. 실제 원인이 맞는지 검증하기 위해 사용했던 쿼리에 대한 실행 계획을 점검했습니다.
# 실행계획을 조회한 쿼리
select h.*
from hashtag as h
join mogako_hashtag as mh on h.id=mh.hashtag_id
where h.name like 'spring %' escape ''
group by h.id
order by count(h.id) desc
limit 5;
EXPLAIN

Extra 컬럼에 표시된 값들 중 성능 병목의 주된 요인이 무엇일지 분석해보겠습니다.
hashtag 테이블
- Using filesort
- 위에서 작성한 쿼리는 해시태그의 매핑 횟수를 기준으로 내림차순 정렬하기 위해 count() 집계함수의 결과를 기준으로 ORDER BY를 사용하고 있습니다. 이 때 적절한 인덱스를 사용할 수 없어 정렬 대상 레코드들을 별도의 정렬용 버퍼에 전부 복사해서 정렬을 수행하게 됩니다.
- 일반적으로 수 많은 레코드를 정렬할 때 버퍼에 이를 복사하는 것은 성능적으로 굉장한 저하를 발생시키는 것이 맞지만, 지금의 경우는 hashtag 테이블의 row가 15줄 밖에 되지 않기 때문에 직접적인 성능적 영향은 미미하다고 판단했습니다.
- Using temporary
- GROUP BY와 ORDER BY를 서로 다른 컬럼에 대해 수행해야 되기 때문에 그 과정에서 임시테이블을 생성하게 됩니다.
mogako_hashtag 테이블
- Using join buffer (hash join)
- hashtag 테이블과 mogako_hashtag 테이블 간의 조인 연산에서 조인 버퍼를 사용한다는 것을 의미합니다.
- 이는 두 테이블에 모두 조인 연산에서 사용할 수 있는 적절한 인덱스가 존재하지 않기 때문입니다.
이렇게 실행계획만 살펴봤을 때는 두 테이블 간 내부 조인 연산 과정이 성능 병목의 주된 원인이지 않을까라고 생각했습니다. 모각코 일정과 실제로 매핑된 해시태그 개수를 각각 count하기 위해 내부 조인 연산을 수행한다는 것을 유추할 수 있는데, 모각코 해시태그 레코드가 150만건인 경우에는 이 150만번의 조인 연산 + count 작업 수행을 위한 풀테이블 스캔으로 150만개 레코드의 조회가 이뤄져야 하기 때문입니다.
EXPLAIN ANALYZE
실제로 앞서 추측한 부분이 성능 병목의 원인이 맞는지 검증하기 위해 EXPLAIN ANALYZE 명령어 통해 실제로 수행된 처리 과정을 살펴보겠습니다.

안쪽 순서대로 살펴보겠습니다.
- 먼저 hashtag 테이블의 name 컬럼을 기준으로 'spring ' 문자열이 prefix로 포함되는 레코드를 필터링합니다.
- 총 15개의 행에서 10개의 행을 필터링하는데까지 0.141 ms가 소요되었습니다.
- 이후 mogako_hashtag 테이블과의 hash join을 위해서 앞서 필터링한 10개의 레코드들을 hash에 저장합니다.
- mogako_hashtag 테이블을 풀스캔하며 hashtag_id를 기준으로 Inner Hash Join을 수행합니다.
- mogako_hashtag 테이블의 150만 개의 레코드들을 전부 스캔하며 앞서 미리 저장해둔 hash의 레코드들과 Inner Join 연산을 수행합니다.
- 조인 결과 약 100만 건의 레코드가 조회되었음을 확인할 수 있습니다.
- 두 작업 모두 합쳐서 대략 272ms 정도 소요되었습니다.
- 임시 테이블을 활용하여 count() 집계함수를 처리한 뒤, 내림차순 정렬 수행 후 상위 5개 레코드를 반환합니다.
- 단계 별로 나뉘어져 표기되어 있기는 하지만, 임시테이블을 활용해 집계함수를 처리하는 과정부터 limit 구문 처리까지 연속으로 함께 처리되며 종료시간이 569~570ms에서 기록된 것을 확인할 수 있습니다.
- 주목해볼만한 부분으로, 집계 작업 이후는 1ms도 걸리지 않았지만 이전의 집계 작업을 처리하는데는 대략 569ms 정도로 가장 큰 시간이 소요되었다는 것입니다.
위에 정리한 내용을 토대로, 쿼리를 처리하는 과정에서 시간이 오래 소요되는 부분은 mogako_hashtag와 hashtag 테이블을 조인하고, count() 집계 처리를 하는 단계라고 확신했습니다.
이를 해결하기 위한 방법을 고민해본 결과, hashtag 테이블에 count 컬럼을 별도로 추가하는 반정규화 작업이 필요하다고 판단했습니다. 일반적으로 쿼리 조회 속도를 개선하기 위해 인덱스 생성을 고려하는데요, count() 집계 처리를 위해서 결국 150만 개의 레코드를 풀스캔하는 것을 피할 수 없어서 인덱스를 생성해주는 것은 큰 의미가 없다고 판단했습니다. 추가적으로, 애시당초 두 테이블을 조인하는 이유도 count 집계 처리를 위해서 였으니 hashtag 테이블에서 count 컬럼을 추가해서 관리를 하고 있다면 주된 성능 병목의 원인을 제거할 수 있다고 생각했습니다.
성능 개선

@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Hashtag extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private Long count;
private Hashtag(String name) {
this.name = name;
this.count = 0L;
}
...
}
성능 병목이 발생하는 지점을 추론하고 이를 검증하는 과정은 오래걸렸지만, 성능 개선 과정 자체는 상대적으로 굉장히 심플했습니다.
우선적으로 hashtag 엔티티와 테이블에 count 컬럼을 별개로 추가해줬습니다. 이후 update 쿼리를 이용해 hashtag의 count 컬럼 값들을 갱신해줬습니다.

이렇게 테이블이 반정규화되어 count 값이 hashtag 테이블 내에서 관리되므로, 기존 쿼리에서 더 이상 조인 연산은 필요하지 않게 되었습니다. 따라서 아래와 같이 기존 jpql 쿼리를 수정해줬습니다.
// @Query("select h " +
// "from Hashtag h inner join MogakoHashtag mh on h.id = mh.hashtag.id " +
// "where h.name like :word% " +
// "group by h.id " +
// "order by count(h.id) desc " +
// "limit 5")
@Query("select h from Hashtag h where h.name like :word% order by h.count desc limit 5")
List<Hashtag> findTop5ByNameStartingWith(@Param("word") String word);
결과적으로 조인 연산과 count 집계 작업 자체를 걷어낼 수 있었습니다. 일련의 리팩터링 과정을 거친 뒤 다시 한 번 150만 건 데이터에 대해 똑같이 성능 측정을 해본 결과는 아래와 같았습니다.
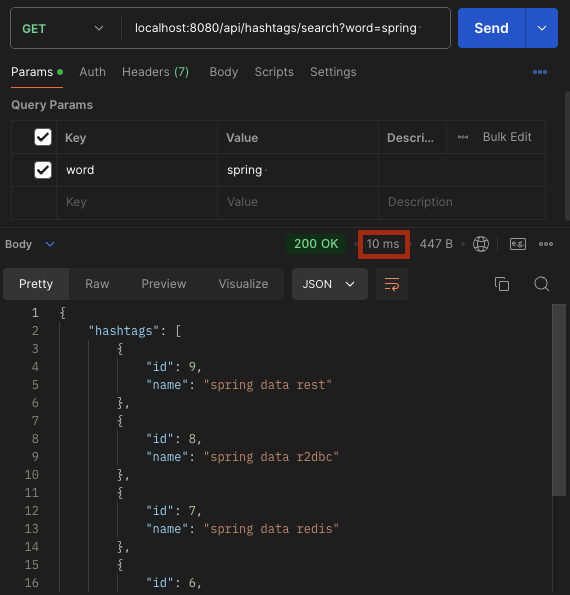
이렇게 761ms 이상 소요되던 조회 API 성능을 10ms 이내의 성능으로 개선할 수 있었습니다. 이제는 모각코 일정에 매핑되는 해시태그 개수가 많이 늘어나도 해시태그 검색어 자동완성 및 추천 API는 요구사항을 충족할 수 있게 되었습니다.
해시태그 개수는 어떻게 업데이트 해야할까?
hashtag 테이블에 기존에는 관리하지 않았던 count 컬럼이 추가되면서 이를 어떻게 관리할 것인지 결정해야 했습니다.
모각코 일정에 해시태그를 매핑할 때마다 개수를 관리하는 방식은 상당히 번거롭다고 생각했습니다. 모각코 일정이 삭제되는 경우도 그렇고 매번 hashtag 테이블의 데이터를 함께 갱신해줘야 하는데 그렇게까지 실시간으로 정보가 정확하게 반영되어야 하는 부분은 아니라고 판단했습니다.
또한 아직 다루지 못했던 문제, 해시태그 개수 자체가 늘어나는 경우에 대해 성능 개선을 진행할 때 인덱스를 도입할 것으로 예상하고 있는데, 이 때 오히려 매번 count 값을 갱신하는 것이 잠재적인 성능 병목 요인이 될 수 있다고 판단했습니다. 이러한 생각을 거쳐 스프링 스케쥴러를 활용해서 매일 새벽 5시마다 한 번씩 hashtag 테이블의 count 컬럼을 갱신하도록 설계했습니다.
@Slf4j
@Component
@RequiredArgsConstructor
public class OneDayScheduler {
private final HashtagRepository hashtagRepository;
@Scheduled(cron = "0 0 5 * * ?")
@Transactional
public void updateHashtagCountJob() {
log.info("scheduler 실행");
try {
hashtagRepository.updateHashtagCount();
} catch (Exception e) {
log.warn("* Scheduler 시스템이 예기치 않게 종료되었습니다. Message: {}", e.getMessage());
throw e;
}
}
}
마무리
이렇게 150만건의 데이터에서도 10ms 이내의 성능을 보여주는 해시태그 검색어 자동완성 기능 개발을 완료했습니다. 사실 이 정도 단계에서도 당장 서비스를 운영하는데에는 크게 문제가 없다는 생각이 들었습니다. 하지만 앞서 예상했던 두가지 문제점 중 하나를 아직 해결하지 못했는데요, 이를 정리해보면 다음과 같았습니다.
- 해시태그 레코드 개수 자체가 늘어나는 경우에 대한 성능 측정이 이뤄지지 않았습니다.
- 현재는 모각코 일정에 매핑되는 해시태그 개수가 많이 늘어날 때 발생하는 성능 문제를 개선한 것이지, 해시태그 레코드 개수 자체가 늘어나는 경우에는 다른 성능 이슈가 발생할 가능성이 농후합니다.
생각보다 포스팅이 길어져서 이번 단계에서는 이정도로 마무리 짓고, 다음 포스팅에서 위에 언급한 부분들을 추가적으로 개선해보도록 하겠습니다.
다음 포스팅
'개발기록 > 사이드 프로젝트' 카테고리의 다른 글
| 해시태그 검색어 자동완성 기능 개발기 3 - 캐싱 (6) | 2024.11.04 |
|---|---|
| 해시태그 검색어 자동완성 기능 개발기 2 - 인덱스 (4) | 2024.10.21 |