
(이전 포스팅에서 이어집니다.)
해시태그 검색어 자동완성 기능 개발기 1 - DB 조회
들어가면서
앞선 포스팅에서 해시태그 레코드 개수 자체가 150만 건까지 늘어나는 경우에도 목표 성능을 유지할 수 있도록 커버링 인덱스와 dto 프로젝션을 적용했습니다. 하지만 잠재적인 문제점은 여전히 남아있었습니다.
- 커버링 인덱스를 사용한다고 하더라도, count 컬럼에 따른 filesort 작업을 매 쿼리마다 수행해야 한다는 점입니다.
- 현재는 해시태그 데이터들을 무작위 문자열로 생성해서 넣어둔 상태라서, 특정 문자열을 prefix로 가지는 레코드 개수에 쏠림 현상이 발생하지 않습니다.
- 예를 들어, 매우 극단적인 경우 's'로 시작하는 해시태그만 100만개가 존재할 수 있습니다.
- 이 경우 's' 로 시작하는 해시태그 검색 시 꼼짝없이 이 100만개에 대한 해시태그 레코드에 대한 인덱스 풀스캔과 별도의 filesort 과정을 거쳐야만 합니다.
- 실제 서비스에서 생성되는 해시태그 데이터들은 위에서 언급한 것처럼 특정 prefix 문자열에 쏠림 현상을 보여줄 수 있기 때문에 특히 첫글자 prefix 문자열에 대한 탐색 시 성능이 확 튈 수 있습니다.
- 현재는 해시태그 데이터들을 무작위 문자열로 생성해서 넣어둔 상태라서, 특정 문자열을 prefix로 가지는 레코드 개수에 쏠림 현상이 발생하지 않습니다.

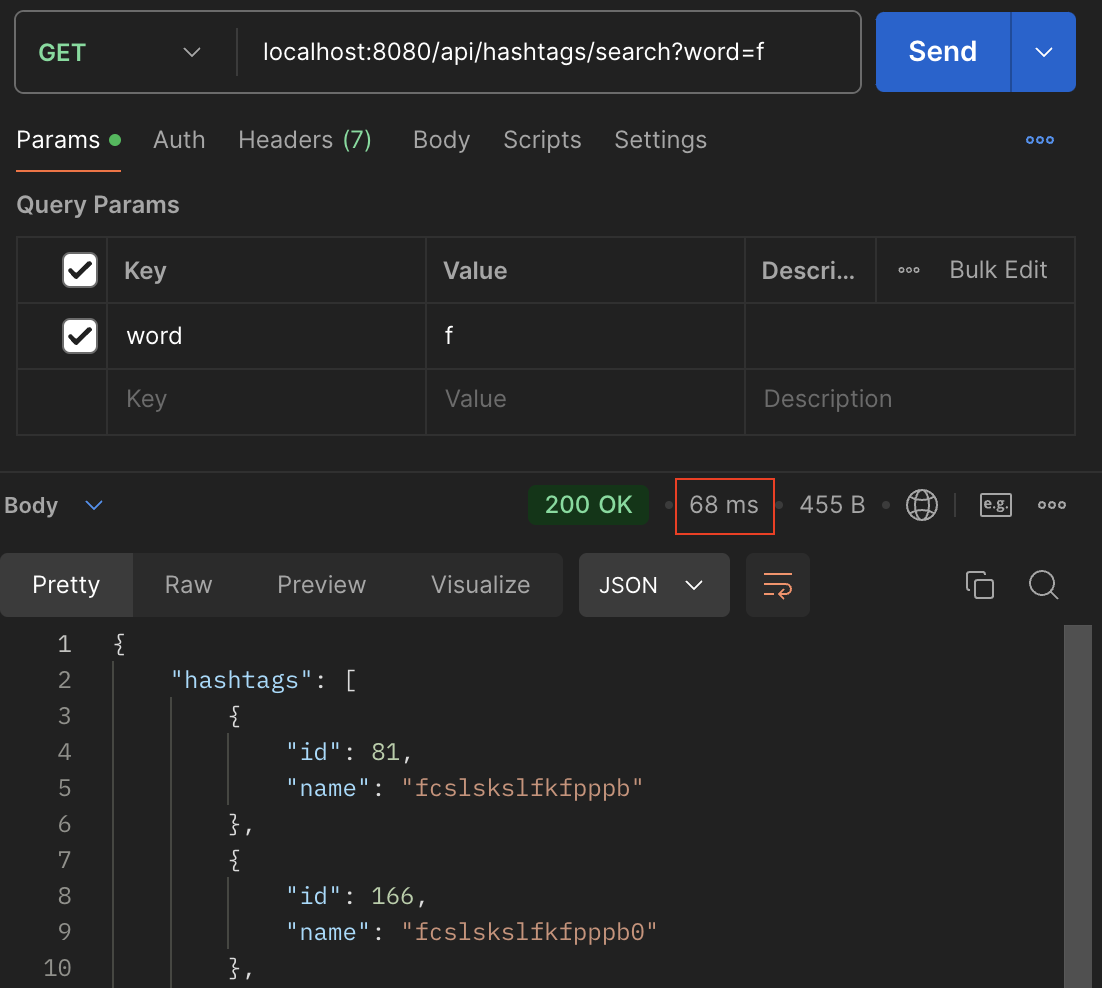
'f'로 시작하는 해시태그 레코드 105,000 건에 대해서는 커버링 인덱스를 사용한다고 해도, 별도의 filesort 과정으로 인해 68ms 의 응답 시간이 나오는 것을 확인할 수 있습니다. 이를 미루어 예측해보면, 'f'로 시작하는 해시태그 레코드가 100만 건이 되었을 때는 기존 요구사항의 목표였던 100ms의 응답 시간을 충족하기 힘들다는 결론을 쉽게 내려볼 수 있었습니다. 이러한 문제점을 극복하기 위한 방안으로 캐싱 전략을 설계해서 적용해보기로 했습니다.
왜 캐싱을 하는가?
캐싱 전략을 설계하기에 앞서, 위에서 언급한 문제점을 해결하기 위해 왜 캐싱이라는 방법을 선택했는지에 대한 근거를 정리해보고자 합니다.
먼저 문제점으로 언급했던 매 쿼리 요청마다 발생하는 filesort 작업을 생략할 수 있기 때문입니다. 사용자가 입력하는 문자열에 대한 상위 5개의 해시태그 응답을 미리 캐싱을 해둔다면, 처음 캐시 데이터를 적재하는 과정에서만 filesort를 거치고 이후에는 모두 캐시에서 응답이 반환되기 때문에 filesort로 인한 성능 저하를 극복할 수 있다고 생각했습니다.
여기에 대해 고민하는 과정에서 Redis나 ElasticSearch 등의 스택을 활용해서 검색어 자동완성 기능을 구현하는 레퍼런스들을 많이 접하게 되었습니다. 하지만 이를 선택하지 않은 이유로는 다음과 같았습니다.
- 우선 ElasticSearch는 처음 환경 세팅하는 과정부터가 매우 복잡했으며, 이를 지속적으로 사용하는데 들여야 하는 러닝커브 비용이 굉장히 크다고 생각하여 선택하지 않았습니다. 물론 배보다 배꼽이 커지는 방향의 선택이라고 생각했던 부분도 컸습니다.
- Redis는 ElasticSearch에 비해서 상대적으로 러닝커브는 낮다고 생각되는 부분도 있었습니다만, 이미 150만건의 레코드에 대해서 준수한 성능을 보여주고 있는 기존 기능을 다시 Redis를 기반으로 구현하고 싶지는 않았습니다. 또한 앞서 고민해왔던 문제점들이 뚜렷하게 해결될만한 솔루션이 보이지 않았던 부분도 컸습니다.
이러한 근거들을 기반으로 가장 간단한 방식인 캐싱을 통해 문제를 해결하는 것으로 결정했습니다.
캐싱 데이터 생성 과정 설계
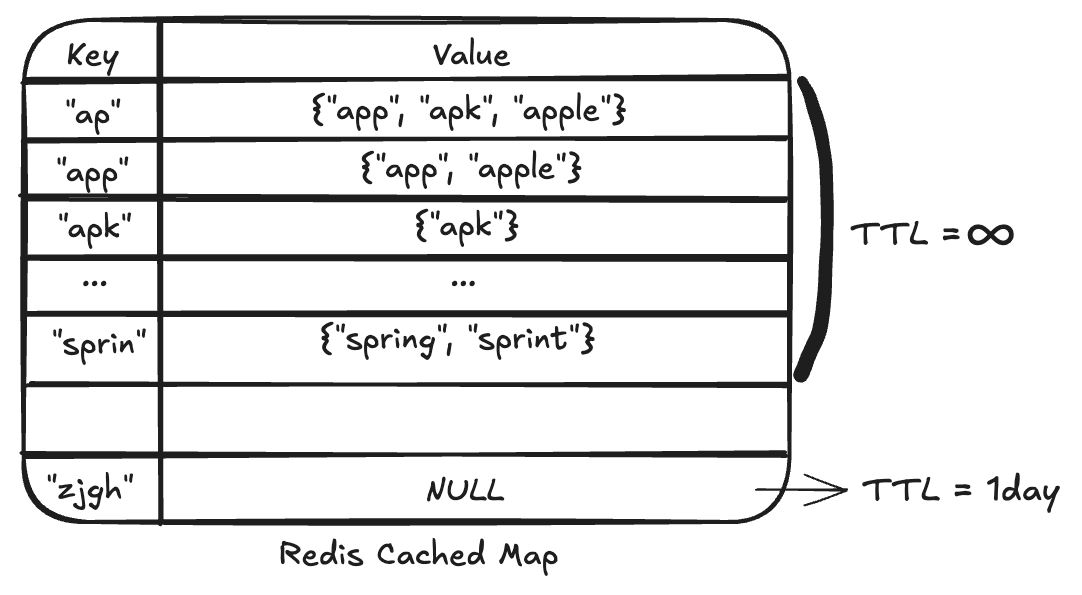
먼저 해시태그 prefix 검색어에 대한 결과를 어떤 방식으로 캐싱해야 할지가 처음 설계 고민의 시작점이었습니다. 단순하게 생각해보면 사용자가 입력하게 되는 prefix 문자열을 key로 가지고, 해당 문자열 prefix에 대한 기존 쿼리 결과인 상위 5개의 추천 해시태그 데이터를 value로 갖는 HashMap을 사용하면 되지 않을까라고 생각했습니다. 모든 데이터가 캐싱되어 있다면, 사용자 입력 문자열이 주어졌을 때 O(1)의 복잡도로 결과를 바로 반환할 수 있으니 캐싱에 사용할 자료구조를 결정하는데에는 큰 어려움은 없었습니다. 완성된 캐싱용 map 데이터는 아래 표와 같은 형태일 것입니다.

문제는 이 캐싱용 map을 어떻게 초기화할 것인가였습니다. 기존 요구사항에서 해시태그 이름의 최대 길이는 20으로 제한해뒀었는데요, ASCII 코드 기준 영어 소문자 알파벳은 각각 1byte 입니다. 만약 알파벳 20자로 만들 수 있는 모든 단어에 대한 경우의 수를 모두 계산해서 캐싱을 한다면 단순하게 계산해봐도 대략 26^20 = 1.99281489 * 10^{28} byte 이라는 어마무시한 데이터가 발생하게 됩니다. 이 데이터를 모두 캐싱하는 것은 불가능하다고 판단했습니다.
그래서 DB에 존재하는 해시태그 데이터들을 기준으로 만들 수 있는 검색 단어 후보군에 대해서만 캐싱을 하는 방향으로 전략을 설계하고자 했습니다. 여기에서 고민 포인트는 "어떻게 이 검색 단어 후보군을 만들어야할까?" 였습니다. 단순하게 생각해보면 각 해시태그 값을 읽어서 만들 수 있는 prefix 단어 별로 set 자료구조에 넣어가며 완성시켜가는 방법을 사용해볼 수 있을 것 같았습니다. 하지만 이후에 각 prefix 단어별로 응답 값을 캐싱하는 과정에서 매번 DB 요청을 통해 응답을 캐싱해야 한다고 생각하니 한번의 캐싱용 map을 생성하는데 너무 큰 네트워크 비용과 DB 부하가 발생할 것이라고 생각했습니다.

이 네트워크 비용과 DB 부하를 낮출 수 있는 방법을 고민한 결과, 해시태그 자동완성 응답을 DB에 매번 요청해서 받지 않고, 별도의 작업 서버 메모리 단에서 캐싱용 map을 완성하는 방법을 선택하기로 했습니다. 이 방법을 선택하게 된 이유를 정리하면 다음과 같았습니다.
- 캐싱용 map을 만드는데 필요한 네트워크 비용과 DB 부하를 줄이는 대신, 외부 작업 서버의 리소스를 이용해서 작업을 수행하는 것이 더 합리적이라고 생각했습니다.
- 저희 서비스에서는 근시일 내로 DB보다는 WAS를 다중화하게 될 가능성이 상대적으로 높습니다.
- 이 때, 여러 WAS의 요청들을 처리하는 단일 DB 서버의 리소스를 사용할 것이냐, 아니면 캐싱용 데이터를 작업하기 위한 별도의 작업 서버 리소스를 사용할 것이냐로 나눠서 생각해본다면 후자가 더 합리적이라고 생각했습니다.
- 또한 캐싱용 map을 완성하는 과정에서, DB 서버의 filesort 작업에 대한 부담을 완전히 걷어낼 수 있다는 점 또한 장점으로 취할 수 있다고 판단했습니다.

이제 고민의 중점은 작업 서버에서 어떻게 캐싱용 map을 완성시킬 것인가로 옮겨졌습니다. 이를 고민하던 중 Trie 자료구조에 대해 알게 되었습니다. Trie 자료구조에 대한 설명은 다른 레퍼런스들이 많기 때문에 간단하게만 하고 넘어가자면, 여러 문자열을 저장해서 빠르게 탐색하기 위한 트리 형태의 자료구조입니다. {apk, app, apple, spring, sprint} 이렇게 다섯 개의 단어에 대해 생성된 Trie 는 아래 예시 그림과 같습니다.

DB에서 조회한 해시태그 데이터들을 기반으로 Trie 자료구조를 완성시킨 이후, Trie를 순회하며 자동완성 검색어 응답을 캐싱하면 최소한의 DB 요청과 prefix 단어 개수로 캐싱 데이터 map을 완성시킬 수 있을 것이라고 생각했습니다. 구체적으로 Trie 자료구조를 사용해서 캐싱 데이터 map을 완성하는 로직을 정리해보면 다음과 같았습니다.

- 먼저 DB에 저장된 해시태그 데이터들을 차례대로 읽어옵니다. 매우 많은 건수가 저장되어 있을 수 있으므로 페이지 단위로 개수를 정해서 읽어올 수 있도록 합니다.
- 읽어온 해시태그 데이터들을 Trie 자료구조에 순차적으로 삽입하며 트리를 완성합니다.
- 각 노드에는 해시태그 prefix 문자열이 저장됩니다.
- 완성 단어 노드에는 온전한 해시태그 이름과 사용 횟수가 함께 저장됩니다.
- DB의 모든 해시태그 데이터를 삽입할 때 까지 1~2번 과정을 반복합니다.
- 완성된 Trie 자료구조의 노드들을 순회하며 해당 노드의 prefix 문자열이 입력되었을 때 반환할 상위 5개 해시태그 값들을 추출하여 저장합니다.
- 정렬 순서는 해당 prefix 문자열을 갖는 해시태그 중 사용 횟수가 많은 순으로 수행합니다.
- 모든 노드에 대한 상위 5개 키워드 추출 작업까지 마무리 되었다면, 각 노드의 prefix 단어와 그에 해당하는 상위 5개 해시태그 값들을 key - value 쌍으로 캐싱용 map 자료구조에 저장합니다.
위와 같은 방식으로 캐싱용 map을 완성하는 과정을 설계했을 때 얻을 수 있는 이점은 다음과 같이 정리될 수 있습니다.
- 응답 데이터 캐싱을 위한 정렬 과정을 별도 작업 서버에서 수행하게 되기 때문에 DB에서 처음 해시태그 데이터를 읽어오고 난 뒤에는 추가적인 네트워크 비용과 DB 부하가 발생하지 않습니다.
- Trie 자료구조에 삽입할 해시태그 데이터를 조회하는 DB 요청 외에는 네트워크 비용이 발생하지 않게 됩니다.
- 이후 정렬해야하는 데이터 작업량이 극단적으로 많아져도, 외부 작업 서버의 스펙을 변경해주는 방향이 DB에서 정렬을 수행할 때보다 훨씬 더 수월하게 대처할 수 있습니다. (Scale Up, Scale Out)
캐싱 정책 설계
다음은 위 과정을 거쳐 완성된 캐싱용 map을 어디에 어떤 방식으로 저장하고 관리할 것인지 캐싱 정책을 결정해야 했습니다. 일단 어디에 캐싱용 map을 저장할 지에 대해서는 크게 두가지 방법이 있었는데요.
- WAS 서버 메모리에 적재한다.
- 장점
- 응답 데이터를 조회하기 위한 네트워크 비용을 절감하고 메모리에서 바로 응답을 반환할 수 있습니다.
- 단점
- WAS 서버가 다중화되면 각 서버 별로 캐시 데이터의 정합성이 틀어질 가능성이 높고, 캐시 미스 시 대처하기 어렵습니다.
- 캐싱용 map의 큰 용량이 WAS 서버 메모리의 대부분을 점유할 위험이 있습니다.
- 장점
- 별도의 캐시 서버에 적재한다.
- 장점
- WAS 서버가 다중화 되어도 캐시 데이터의 정합성이 유지되며, 캐시 미스 시에도 캐시 서버에만 처리를 해주면 되기 때문에 비교적 대응하기 쉽습니다.
- WAS 서버의 메모리를 점유하지 않기 때문에 기존 API 작업에 영향을 주지 않습니다.
- 단점
- 캐시 데이터를 조회하기 위한 요청으로 인해 네트워크 비용이 발생합니다.
- 장점
이렇게 각 방법의 장단점을 비교해봤을 때, 별도의 캐시 서버를 구축해서 데이터를 적재할 때 얻을 수 있는 장점이 네트워크 비용 발생 정도보다 훨씬 크다는 생각이 들어 두 번째 방안을 채택하기로 결정했습니다.
추가적으로 별도의 캐시 서버는 Redis를 사용해 구축하기로 결정했습니다. 가장 큰 이유는 Redis에서 기본적으로 제공하는 TTL (Time To Live) 기능을 캐싱 정책에 사용하기 위해서입니다. 맨 처음 캐싱용 map을 적재한 이후 발생하는 캐시 관통(Cache penetration) 현상을 방지하기 위해 null object 패턴을 캐싱 정책으로 사용하고자 했는데요, 이렇게 하나씩 null object가 쌓이다보면 앞서 계산했던 것처럼 최대 26^20 = 1.99281489 * 10^{28} byte 크기의 데이터가 쌓일 수 있기 때문에 무지성으로 캐시에 추가하는 것은 위험하다고 판단했습니다. 그래서 이를 방지하면서 null object 패턴을 사용하기 위해 초기 map 데이터 적재 이후 추가되는 데이터들은 TTL을 설정해서 일정 시간 이후 삭제될 수 있도록 했습니다.
구현하기
우선 DB에서 해시태그 데이터를 페이지 단위로 조회하면서, Trie 자료구조를 초기화하고 캐싱용 map을 생성하는 로직을 구현했습니다.
private Map<String, List<HashtagResponse>> generateCacheMap() {
// create new trie instance
Trie trie = new Trie();
// init trie with first page
PageRequest request = PageRequest.of(0, 10000);
Page<Hashtag> hashtagPage = hashtagRepository.findAll(request);
for (Hashtag hashtag : hashtagPage.getContent()) {
trie.insert(hashtag.getId(), hashtag.getName(), hashtag.getCount());
}
//init trie with other pages
int totalPages = hashtagPage.getTotalPages();
for (int pageNum = 1; pageNum < totalPages; pageNum++) {
request = PageRequest.of(pageNum, 10000);
hashtagPage = hashtagRepository.findAll(request);
for (Hashtag hashtag : hashtagPage.getContent()) {
trie.insert(hashtag.getId(), hashtag.getName(), hashtag.getCount());
}
}
// generateCacheMap
trie.cacheTopWords();
return trie.getCachedTopWords();
}
캐싱용 map 생성 작업을 구현한 코드의 실행 흐름을 간단하게 정리해보면 다음과 같습니다.
- 페이지네이션 단위로 해시태그 데이터 읽어와서 trie 객체에 삽입하며 트리 구조를 완성시킵니다.
- 완성된 trie 객체를 통해 전체 노드들을 순회하면서 캐싱용 map을 초기화시킵니다.
- 초기화된 캐싱용 map을 결과값으로 반환합니다.
- 캐싱용 map은 prefix 문자열을 key로 가지고, value로 반환해야 하는 해시태그 응답값 리스트를 저장합니다.
이후에는 초기화된 캐싱용 map을 레디스 캐시 서버에 영속화합니다. 이 때 HashtagResponse dto 리스트를 그대로 캐시 서버에 문자열 형태로 저장할 수 있도록 objectMapper를 활용해 직렬화를 수행합니다. 여러 HashtagResponse 객체들의 리스트를 value로 저장해야 했는데, 이를 굳이 엔티티로 구현할 필요를 느끼지 못했고 RedisRepository를 사용하면 오히려 더 직관성이 떨어질 것 같다고 판단했기에 간단하고 직관적으로 redisTemplate을 사용해서 key, value 문자열 쌍을 영속화할 수 있도록 했습니다.
public void initializeHashtagCacheMap() {
Map<String, List<HashtagResponse>> cacheMap = generateCacheMap();
// save cacheMap to redis
ValueOperations<String, String> valueOps = stringRedisTemplate.opsForValue();
try {
for (Entry<String, List<HashtagResponse>> entry : cacheMap.entrySet()) {
String prefixWord = entry.getKey();
String value = objectMapper.writeValueAsString(entry.getValue());
valueOps.set(prefixWord, value);
}
} catch (Exception e) {
throw new ConvertObjectException();
}
}
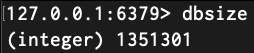
위 일련의 과정들을 거쳐 캐싱용 map 생성을 완료하고 무사히 Redis 캐시 서버에 적재할 수 있었습니다. 대략 135만건의 prefix 문자열들에 대한 응답값들이 각각 캐싱되었음을 아래 이미지와 같이 확인할 수 있었습니다.
그 다음은 앞서 설계한 방식대로 캐시 서버를 적절하게 조회하고, 캐시 미스 시 캐시 정책에 따라 새로운 데이터를 적재할 수 있도록 해시태그 자동완성 API를 수정했습니다.
private List<HashtagResponse> getDatabaseResultWithCaching(String word, ValueOperations<String, String> valueOps) {
// cache miss
List<HashtagProjectionDto> autocompletedHashtags = hashtagRepository.findProjectionDtoTop5ByNameStartingWith(word);
List<HashtagResponse> responses = autocompletedHashtags.stream()
.map(HashtagResponse::from)
.toList();
// cache db read result
try {
String value = EMPTY_HASHTAG_RESULT_VALUE;
if (!responses.isEmpty()) {
value = objectMapper.writeValueAsString(responses);
}
valueOps.set(word, value, 1L, TimeUnit.DAYS);
} catch (Exception e) {
throw new ConvertObjectException();
}
return responses;
}
먼저 사용자의 요청이 캐시 미스일 때 이를 처리하는 로직입니다. DB에 캐시 미스가 발생한 prefix 문자열에 대해 조회를 요청합니다. 이 때 결과 값은 다음과 같은 2가지 경우로 나눌 수 있습니다.
- 캐싱용 map을 생성한 이후에 추가된 새로운 해시태그 데이터가 존재합니다. (DB 조회 결과 값 존재)
- 여전히 아무런 데이터가 없을 수도 있습니다. (DB 조회 결과 값 부재)
그래서 DB에서 조회 결과 값이 존재하지 않을 때는 미리 약속해둔 빈 문자열 값을 value로 해서 캐시 미스가 발생한 prefix 문자열을 key로 하는 key - value 쌍을 redis에 저장합니다. 반대로 DB 조회 결과 값이 존재하는 경우에는 직렬화를 통해 HashtagResponse 객체 리스트를 문자열로 변환하여 저장할 수 있도록 구현했습니다.
이렇게 캐시 미스 시 처리 로직을 구현한 뒤, 수정을 완료한 해시태그 검색어 자동완성 API의 로직은 다음과 같았습니다.
public HashtagsResponse findAutocompleteHashtags(String word) {
ValueOperations<String, String> valueOps = stringRedisTemplate.opsForValue();
String value = valueOps.get(word);
if (Objects.nonNull(value)) {
// cache hit
try {
List<HashtagResponse> hashtagResponses = new ArrayList<>();
if (!value.isEmpty()) {
hashtagResponses = objectMapper.readValue(value, new TypeReference<>() {});
}
return HashtagsResponse.from(hashtagResponses);
} catch (Exception e) {
throw new ConvertObjectException();
}
}
// cache miss
List<HashtagResponse> responses = getDatabaseResultWithCaching(word, valueOps);
return HashtagsResponse.from(responses);
}
사용자가 입력한 prefix 문자열 값을 key로 하는 데이터 쌍이 존재하는지 redis 캐시 서버를 먼저 조회합니다. 이후 캐시 히트가 발생했다면, value 문자열을 다시 역직렬화해서 바로 반환할 수 있도록 했습니다. 그리고 캐시 미스 발생시에는 앞서 설계했던 로직 수행 이후 응답 값을 반환하도록 했습니다.
여기까지 해서, 기존 해시태그 검색어 자동완성 API에 캐싱 기능 도입을 성공적으로 완료할 수 있었습니다.
성능 개선
이제 수정된 해시태그 검색어 자동완성 API에서는 DB에 저장된 해시태그 데이터로 만들 수 있는 모든 prefix 문자열에 대한 응답 값들이 저장된 캐시 서버를 항상 먼저 조회하므로, 맨 앞에서 단일 알파벳에 대한 검색을 수행할 때 성능이 튀는 현상이 해결할 수 있었습니다. 실제로 수정된 API를 통해 똑같이 'f' 라는 문자열에 대해서 요청을 했을 때 측정된 성능은 다음과 같았습니다.

10만 건의 해시태그 데이터에 대해서 약 68ms를 기록했던 기존 성능에 비해 지금은 캐싱 데이터를 바로 조회해오기 때문에 7ms 이내로 처리를 완료하는 것을 확인할 수 있었습니다. 물론 캐시 미스가 발생했을 때는 DB를 조회하는 과정에서 다시 성능이 튈수도 있지만, 해당 값 또한 다시 캐싱될 것이기 때문에 적어도 그 하루동안은 동일한 요청에 대해 다시 캐시 미스가 발생하지 않게 됩니다.
항후 개선 방향성
원래 캐싱용 map 데이터를 생성하는 작업 서버를 따로 구축하는 것이 정석이었으나, 현재 150만건의 데이터에 대해서 직접 수행해본 결과 아직은 WAS 내에서 이를 처리해도 충분하겠다고 판단했습니다. 앞에서도 언급했었듯이 데이터가 많아졌을 때 이를 메모리에 전부 올리게 되면 OOM 문제가 발생할 수 있다는 것이 위험 요인이었는데요, 현재 저희 서비스의 WAS 메모리는 4GB로 할당되어 있는데 150만 건에 대해서 작업을 수행할 때 메모리 사용량을 측정해본 결과는 다음과 같았습니다.

해당 작업은 스케쥴러를 통해 일주일에 한번씩, 새벽 시간대에 수행되도록 설정할 것이기 때문에 작업을 수행하며 1.4GB 까지 메모리를 일시적으로 점유하는 것은 크게 부담이 되지 않을 것이라고 판단하여 당장은 WAS에서 수행하는 방향으로 결정했습니다. 이후 실제로 서비스를 운영하면서 해시태그 데이터가 150만건 이상이 된다면 그 때 작업 서버를 구축하고 설계를 변경하기로 했습니다.
마무리
이렇게 캐싱 정책의 도입을 통해 DB 요청마다 매번 발생하던 filesort 작업으로 인한 성능 병목을 개선할 수 있었습니다. 저희 모각코 일정 스케쥴러 서비스에서는 이 정도면 당분간은 충분히 사용할 수 있는 정도까지 성능을 개선했다고 생각이 들어 이 정도에서 작업을 마무리하고자 합니다. 짧지 않은 포스팅을 여기까지 읽어주셔서 감사합니다!
'개발기록 > 사이드 프로젝트' 카테고리의 다른 글
| 해시태그 검색어 자동완성 기능 개발기 2 - 인덱스 (4) | 2024.10.21 |
|---|---|
| 해시태그 검색어 자동완성 기능 개발기 1 - DB 조회 (0) | 2024.10.21 |