해시태그 검색어 자동완성 기능 개발기 2 - 인덱스
(이전 포스팅에서 이어집니다.)
해시태그 검색어 자동완성 기능 개발기 1 - DB 조회
들어가면서
앞선 포스팅에서 해시태그 검색어 자동완성 및 추천 기능을 가장 간단하게 DB에서 필터링하는 방법으로 구현하고 성능 개선을 진행했었습니다. 하지만 예측되는 문제점들 중 아직 해결하지 못한 것들이 남아있었는데요, 내용은 다음과 같았습니다.
- 해시태그 레코드 개수 자체가 늘어나는 경우에 대한 성능 측정이 이뤄지지 않았습니다.
- 현재는 모각코 일정에 매핑되는 해시태그 개수가 많이 늘어날 때 발생하는 성능 문제를 개선한 것이지, 해시태그 레코드 개수 자체가 늘어나는 경우에는 다른 성능 이슈가 발생할 가능성이 농후합니다.
이번 포스팅에서는 해시코드 레코드 개수 자체가 늘어나도 문제가 없도록 API를 개선해보고자 합니다.
성능 측정 및 문제점 분석
현재 hashtag 테이블에는 15개의 레코드만 존재합니다. 그리고 현재 사용되는 쿼리와 성능을 다시 한 번 살펴보면 다음과 같습니다.
public interface HashtagRepository extends JpaRepository<Hashtag, Long> {
@Query("select h from Hashtag h where h.name like :word% order by h.count desc limit 5")
List<Hashtag> findTop5ByNameStartingWith(@Param("word") String word);
}

15건의 hashtag 레코드에 대해서는 처음 정했었던 100ms 이내의 성능을 만족해야 한다는 요구사항을 충족시킬 수 있었습니다. 그러면 이제 점진적으로 hashtag 레코드 개수를 늘려가며 성능 측정을 해보겠습니다. (구체적인 이미지는 접은 글을 펴주시면 보실 수 있습니다.)
15000건
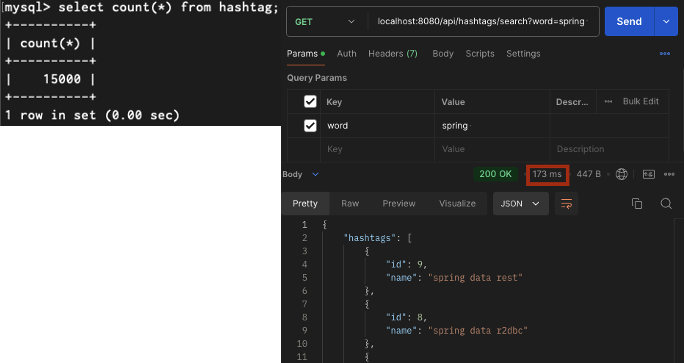
15만건

150만건
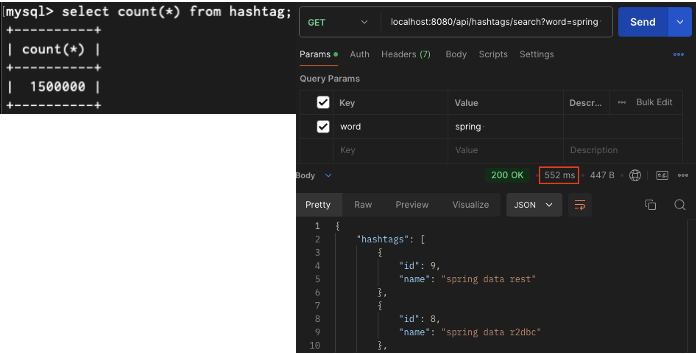
이번에도 성능 측정 결과를 표로 정리해보면 다음과 같았습니다.
| hashtag 테이블 레코드 수 | API 응답 시간 |
| 15건 | 10ms |
| 15,000건 | 173ms |
| 150,000건 | 201ms |
| 1,500,000건 | 552ms |
해시태그 개수가 15,000개를 넘어가는 순간부터 100ms 이상의 응답시간이 발생합니다. 앞선 포스팅에서처럼 조인 연산이나 count() 집계 작업을 처리하지 않음에도 이러한 성능 저하가 발생하는 원인으로는 hashtag 테이블에 적절한 인덱스가 걸려있지 않아 테이블을 풀스캔하기 때문이라고 추론했습니다.
실행계획 점검

현재 사용하는 쿼리의 실행계획을 살펴보면, Extra 컬럼에 Using filesort가 표시되고 있습니다. 이는 hashtag 테이블에 대한 해당 쿼리를 처리하고자 할 때 사용할 수 있는 적절한 인덱스가 존재하지 않기 때문에 별도의 정렬용 버퍼에 레코드를 복사해서 정렬하고 결과를 반환한다는 것을 의미합니다.

EXPLAIN ANALYZE를 통해 실제 쿼리 수행과정을 살펴보면 해시태그 중 주어진 문자열을 prefix로 가지는 레코드를 탐색하기 위해 테이블을 풀스캔하며 filtering하는 과정에서 시간이 가장 많이 소요됨을 확인할 수 있었습니다. 현재 입력된 150만개의 해시태그 데이터의 name 컬럼에는 의미를 갖지 않는 무작위 문자열이 입력되었기 때문에 'spring ' 이라는 문자열을 prefix로 가지는 해시태그를 필터링한 이후 정렬과정에서는 레코드 개수가 많지 않아 1ms 이내에 종료된 것을 확인할 수 있었습니다. (나중에 해당 부분이 잠재적인 문제 요인이 될 수 있다는 내용은 뒤에서 다뤄보도록 하겠습니다.)
이를 통해 hashtag 테이블을 스캔하며 name 컬럼 값을 검사할 때 사용할 수 있는 인덱스를 생성해준다면 유의미한 성능 개선을 이뤄낼 수 있을 것이라는 근거를 얻을 수 있었습니다.
성능 개선
hashtag 테이블의 name 컬럼에 인덱스를 생성해준 뒤 성능 측정을 해보았습니다.

name 컬럼에만 인덱스를 생성해줬음에도 552ms -> 141ms 로 성능 개선이 유의미하게 이뤄졌음을 확인할 수 있었습니다. 하지만 최초 요구사항이었던 100ms 이내의 성능을 만족시키지는 못했기에 추가적인 개선점을 찾아보았습니다.

위 이미지처럼 name 컬럼에는 인덱스가 생성되어 있기 때문에 더 이상 150만 건의 레코드를 풀스캔하지 않고 정확하게 10개의 레코드만 스캔하여 처리하는 것을 확인할 수 있습니다. 이렇게 실행계획만 봤을 때는 더 이상 성능을 개선할만한 부분이 보이지 않는 것처럼 보입니다. 그러면 기존에 사용하던 쿼리를 다시 한 번 살펴봅시다.
select * from hashtag where hashtag.name like 'spring %' escape '' order by hashtag.count desc limit 5;
저는 여기에서 hashtag 테이블 레코드의 모든 컬럼 값을 조회해오는 것에 주목했습니다. name 컬럼에 대한 인덱스를 생성해뒀지만, 전체 컬럼 데이터를 반환해야 하기에 결국에는 실제 레코드에 접근하는 디스크 IO 작업이 발생하게 됩니다. 현재 API 응답 형식을 보면 hashtag 테이블에서 name 컬럼만 필요로하는데 굳이 전체 레코드를 읽어오기 위해 느린 디스크 IO 작업을 감수할 필요는 없겠다고 판단했습니다.
select name, count from hashtag where hashtag.name like 'spring %' escape '' order by hashtag.count desc limit 5;
그래서 위와 같이 API 응답 메세지에 필요한 name 컬럼과 내림차순 정렬에 필요한 count 컬럼만 읽어올 수 있도록 쿼리를 수정했습니다. 또한 두 컬럼의 값을 읽을 때 디스크 IO가 발생하지 않도록 인덱스 또한 name, count 컬럼에 대해 생성해줬습니다.


이후 다시 실행계획을 살펴보면 커버링 인덱스를 통해 hashtag 테이블의 인덱스를 탐색하는 과정이 1.23ms -> 0.112ms 로, 개선됨을 확인할 수 있었습니다.

최종적으로 클라이언트 단에서는 반복적인 요청에도 9ms의 API 응답 시간을 달성할 수 있었습니다.
(552ms -> 9ms 개선)
잠재적인 문제점과 한계
여기까지해서 최대 150만건의 레코드에서도 10ms 이내의 응답 시간을 가진 API로 성능 개선을 할 수 있었습니다. 하지만 잠재적인 문제점은 여전히 존재한다고 생각했는데 이를 정리해보면 다음과 같았습니다.

- 여전히 count 컬럼 값을 기준으로 내림차순 정렬을 위해 filesort를 사용하고 있다는 점입니다.
- 인덱스 생성 이후 실행계획을 다시 확인해보면 여전히 filesort를 사용한다고 표시됩니다. 이는 name 컬럼은 정순으로, count 컬럼은 역순으로 생성해둔다고 해도 name 컬럼에 대한 필터링을 거치고 나서 다시 count 순으로 정렬해야되기 때문에 인덱스 하나만으로는 해결하기 힘든 부분이라고 생각했습니다.
- 이러한 이유 때문에, 해시태그를 입력하기 위해 첫 글자를 입력했을 때 가장 정렬과정에서 오래 시간이 소요될 것이라고 예측했는데요, 실제로 실행계획 살펴보면 's'라고 입력했을 때 가장 오래 걸리고 'spring %' 이런 식으로 단어가 완성되어 갈수록 더 시간이 단축되어가는 것을 확인할 수 있습니다. 이는 글자를 하나만 입력했을 때 정렬해야 하는 레코드의 양이 가장 많기 때문입니다.

마무리
이렇게 해서 해시태그 검색어 자동완성 기능에 대한 1차적인 성능 개선 작업을 완료했습니다. 하지만 마지막에 언급했다시피 잠재적인 문제점과 한계점이 여전히 존재하고 있다는 점이 아쉽습니다. 물론 저희 프로젝트 서비스 차원에서는 이미 충분히 사용할만한 API라고 생각합니다만, 당장 떠오르는 문제점은 백엔드 차원에서 최대한 해결해보고자 합니다. 그래서 다음 포스팅에서는 이런 점을 고려해서 API를 개선해보도록 하겠습니다.
다음 포스팅